自分の書いた記事が狙ったキーワードで検索順位が何位になっているかをチェックしたいと思いましたが、有料の検索順位チェックツールの Rank Tracker や GRC は、そこそこの値段がします。
そこで、pythonで自作することにしました。

完成形
Streamlit Cloudに公開して、常に確認できる状態にしています。
コードはGitHubにアップしています。
検索順位の自動取得
検索順位の自動取得は、「pythonでサイト検索順位を調べるプログラム|ブログ初心者用」を参考にさせていただきました。
自分の環境ではエラーが出て一部修正はありましたが、うまく動きました。
しかしその後、Googleはスクレイピングが禁止だということを知りました。
代替案としては、Google Custom Search APIを使う方法です。
こちらの方法は、現在試している最中なので、また出来たら記事を書きます。
(現在はできる範囲で手動で検索順位を確認しています。)
検索順位をStreamlitで表示
検索順位はスプレッドシートに記録しています。
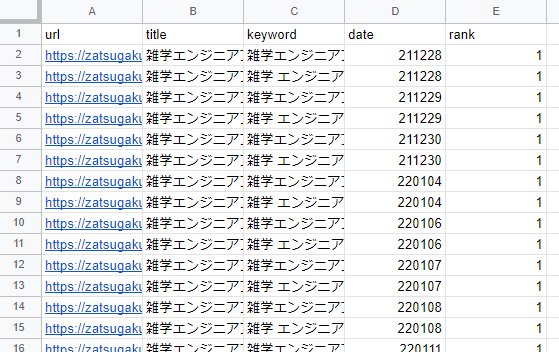
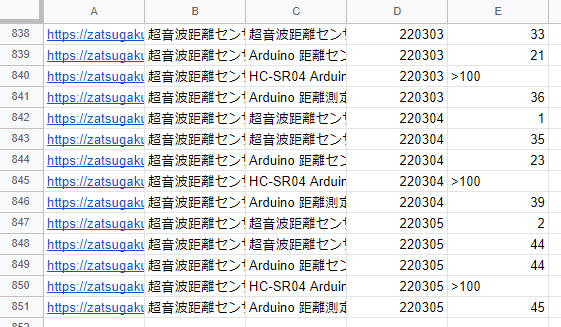
スプレッドシートの内容は下記です。
対象のページのURL、ページタイトル、キーワード、検索した日付、検索順位を格納しています。
100位よりも下の検索順位の場合は >100 で記録しています。
このスプレッドシートからデータを読み取ってStreamlitで表示しています。
Streamlitが何か知らない方は、下記の記事を参考にしてください。

スプレッドシートからデータを読み取り
コードはGitHubにアップしていますが、スプレッドシートからデータを取得する方法について詳しく知りたい方は下記の記事を参考にしてください。

ローカルでデータを取得したい場合
スプレッドシートからではなく、ローカルのcsvファイルからデータを取得したい場合についても記載しておきます。
日々の検索順位を別々のcsvに出力して保存しているとします。
内容はスプレッドシートの内容と同じです。
このスプレッドシートを読み取って、一つのデータフレームに結合すれば、スプレッドシートと全く同じ内容になるとします。
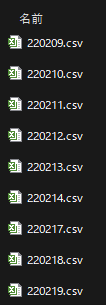
ディレクトリの構成は以下とします。
root/
├ streamlit-graph-maker.py
└ datafile/
└ 220218.csv
└ 220219.csv全てのcsvファイルを読み取って、ひとつのデータフレームにまとめるコードは以下です。
日付が220218という形式になっているので、20220218に変換するコードも合わせて書いています。
def get_data(): # 指定フォルダ内のCSVを全て読み取ってひとつのデータフレームに結合 folder_path = r"data_file" files = glob.glob(folder_path + "\*.csv") lists = [] for file in files: df = pd.read_csv(file, index_col=None, header=0) lists.append(df) df = pd.concat(lists, axis=0, ignore_index=True) # 日付のフォーマットを変更 df['date'] = pd.to_datetime('20' + df['date'].astype(str)) #日付が220101形式なので、20220101形式に変換 df['date'] = df['date'].dt.strftime('%Y-%m-%d') #日付を2022/01/01形式の文字列に変更 df = df.set_index('date') #日付列をインデックスに指定 return dfStreamlitでグラフを表示する方法
スプレッドシートから読み取ったデータをStreamlitでグラフにします。
コードはGitHubにアップしていますが、もっと詳しくStreamlitでグラフを表示する方法について知りたい場合は、下記の記事を参考にしてください。
Heroku や Streamlit Cloud で定期実行
自分のPCで毎回pythonを動かすのは面倒なので、Heroku や Streamlit Cloudを使ってリモートで定期実行をするのがおすすめです。
リモートで定期実行をしておけば、自動で定期的にデータを収集してくれたり、いつでもどこからでもグラフを確認することができます。
Heroku や Streamlit Cloud を知らない方、使い方を知りたい方は、YouTubeの「自動化に欠かせない定期実行の仕組みを3大クラウドで実践!」や、「【Streamlit超入門】データ可視化・分析アプリを爆速で作成できるPythonライブラリStreamlitの基礎を70分でマスター」が参考になります。
また、リモート実行よりもローカルで定期実行したいという場合は、「【超有益】Pythonの定期実行についてわかりやすく解説!(ローカル・リモート環境編)」が参考になります。
Streamlit Cloudを使用する場合のシークレットマネージャーについて
スプレッドシートをPythonで扱う場合は、GCP(Google Cloud Platform)のAPIを使う必要がありますが、Streamlit CloudはGitHubにコードをアップして公開する必要があります。
その場合にAPIキーを非公開にできる仕組みがStreamlit Cloudのシークレットマネージャー(Secrets management)です。
(Herokuの場合は、コードがオープンにならないので、問題ありません。)
シークレットマネージャーの使い方については、以下の記事を参考にしてください。
自分で作成が面倒であれば有料ツールを使うのもおすすめ
自分でツールを作るのは労力がかかるので、有料ツールを使うのもおすすめです。
やはり有料ツールの方が機能が充実しており、使い勝手は段違いに良いです。
無料トライアルを利用したり、使用してみて使い勝手が悪かったらやめればいいです。


