
私はミスチルが20年前から好きで、ある日ふと、歌詞にはどんな単語が多く使われているのだろうと気になりました。
そこで、Pythonを使って調べてみることにしました。
歌詞を分析するために、まずは歌詞を収集しないといけませんが、こちらはスクレイピングを使用して収集しました。
収集方法については以下の記事に書いているので参照して下さい。
 ミスチルの歌詞をスクレイピングで取得してみた【Beautiful Soup】
ミスチルの歌詞をスクレイピングで取得してみた【Beautiful Soup】今回は収集した歌詞をJanomeで単語ごとに分割し、WordCloudで多く使われている単語を可視化してみることにしました。
- Janomeで文章内の単語を分割する方法
- Janomeのいろいろな使い方(分割手法の変更や単語の出現頻度のカウント)
- WordCloudで単語をかっこよく可視化する方法
- ミスチルの歌詞で多く使われている単語(名詞や動詞に分けてわかります)

ミスチルの歌詞で多く使われている単語
今回は2021年9月時点で発表されている曲を対象としています。
分析した結果は以下です。以下は名詞のみを分析・可視化しています。

上記以外にも、動詞や形容詞のみの分析や、Janomeの詳細な使い方を検証しています。
「Janome」と「WordCloud」
Janomeとは
Janomeは文章中の単語を分割できるPythonのライブラリです。
日本語は英語のように単語が分割されていないので文章を単語に分割しようとすると大変ですが、Janomeを使えばとても簡単に単語に分割することができます。
このように文章中の単語を解析する手法を形態素解析といいます。
形態素とは、意味をもつ単語の最小の単位のことをいいます。
形態素(けいたいそ、英: morpheme)とは、言語学の用語で、意味をもつ表現要素の最小単位。ある言語においてそれ以上分解したら意味をなさなくなるところまで分割して抽出された、音素のまとまりの1つ1つを指す。
引用元:Wikipedia「形態素」
Janomeのように形態素解析ができるライブラリで「Mecab」があります。
Janomeに入っている辞書はMecabに入っている辞書と同じ辞書を使っているので、精度は同じですが処理速度はMecabの方が速いようです。
ただし、Janomeの方がpipコマンドで簡単にインストールして使えるので、今回はJanomeを使うことにしました。
WordCloudとは
WordCloudは上の分析結果の画像のように、文章中に入っている単語をカウントし、カウント数が多い順に大きさや色を変えて表示することができます。
今回使用してみて、本当に簡単に使用できて驚きました。
誰かにかっこよく形態素解析の結果を見せるときにおすすめです!
Janomeの使い方とWordCloudで表示する分析結果
Janomeのインストールは簡単です。以下のpipコマンドでインストールします。
pip install janomeWordCloudのインストールも簡単です。以下のpipコマンドでインストールします。
pip install wordcloud今回分析したデータ
収集した歌詞は、csvファイルに出力しています。csvファイルは以下のような内容です。
(実際のデータには具体的な曲名や歌詞が入っています。)

歌詞の収集はスクレイピングで行っています。
下記の記事を参考にしてください。
ミスチルの歌詞をスクレイピングで取得してみた【Beautiful Soup】基本的な使い方と解析結果
まずは基本的な使い方で歌詞を分析してみます。
結果は以下です。
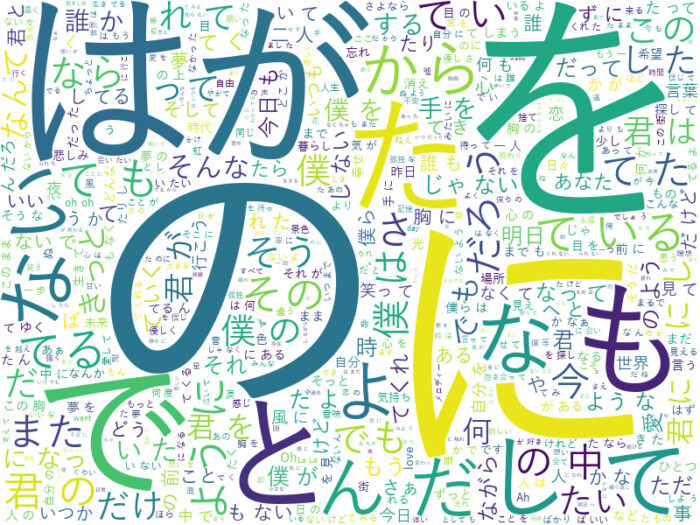
・・・・・よくわかりません。
いろいろな品詞の形態素が入っているので、「の」とか「に」など、あまり意味のない単語が多く含まれています。
コードは以下です。
from janome.tokenizer import Tokenizer
import pandas as pd
import collections
from wordcloud import WordCloud
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
t = Tokenizer()
results = []
for s in song_lyrics: tokens = list(t.tokenize(s, wakati=True)) result = [i.replace('\u3000','') for i in tokens] # 全角スペースを削除 # リストに追加 results.extend(result)
# wordcloud
#日本語のフォントパス
fpath = 'C:/Windows/Fonts/YuGothM.ttc'
text = ' '.join(results) # 区切り文字を「・」にして文字列に変換
# 単語の最大表示数は500に設定
wordcloud = WordCloud(background_color='white', font_path=fpath, width=800, height=600, max_words=500).generate(text)
#画像はwordcloud.pyファイルと同じディレクトリにpng保存
wordcloud.to_file('./wordcloud-mrchildren.png')基本形で解析してみる
上記は「表層形」という形式で解析しています。
文章で使われている単語をそのままの形で解析しています。
例えば「走れ」と「走る」は別々に解析しています。
今回は「基本形」で解析してみます。辞書に登録されている見出し語で解析されます。
「走れ」は「走る」として解析されます。

少し結果は変わりましたが、やっぱりよくわかりません。
コードは以下です。
変更した場所をハイライトしています。
from janome.tokenizer import Tokenizer
import pandas as pd
import collections
from wordcloud import WordCloud
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
t = Tokenizer()
results = []
for s in song_lyrics: tokens = list(t.tokenize(s, wakati=True)) result = [i.replace('\u3000','') for i in tokens] # 全角スペースを削除 # 基本形でリストに追加 results.extend([token.base_form for token in t.tokenize(s)])
# wordcloud
#日本語のフォントパス
fpath = 'C:/Windows/Fonts/YuGothM.ttc'
text = ' '.join(results) # 区切り文字を「・」にして文字列に変換
# 単語の最大表示数は500に設定
wordcloud = WordCloud(background_color='white', font_path=fpath, width=800, height=600, max_words=500).generate(text)
#画像はwordcloud.pyファイルと同じディレクトリにpng保存
wordcloud.to_file('./wordcloud-mrchildren.png')品詞の種類を確認してみる
上記の結果は名詞や動詞以外に助動詞なども含まれるため、分かりづらい結果になっています。
どのような品詞が入っているかを確認し、確認したい品詞のみで解析してみます。
まずは品詞の確認を行います。
品詞は以下のような分類と個数でした。
| 品詞 | 個数 |
|---|---|
| 名詞 | 19,854 |
| 助詞 | 18,293 |
| 動詞 | 11,365 |
| 記号 | 5,775 |
| 助動詞 | 5,007 |
| 副詞 | 1,686 |
| 形容詞 | 1,537 |
| 連体詞 | 877 |
| 接続詞 | 413 |
| 感動詞 | 231 |
| 接頭詞 | 110 |
| フィラー | 29 |
| その他 | 1 |
今回は「名詞」、「動詞」、「形容詞」について確認してみます。
上記を解析したコードは以下です。
from janome.tokenizer import Tokenizer
import pandas as pd
import collections
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
t = Tokenizer()
results = []
for s in song_lyrics: result = [token.part_of_speech.split(',')[0] for token in t.tokenize(s)] results.extend(result)
c = collections.Counter(results)
print(c.most_common())名詞のみ抽出する
まずは名詞のみ解析してみます。
解析した結果は以下です。

「君」や「僕」、「何」、「誰」という名詞が多く使われているようです。
考えてみると、確かに「君」や「僕」はすごく多く使われているように思います。
ただし、「ん」や「よう」など意味が分からない言葉も多く抽出されています。
コードは以下です。
from janome.tokenizer import Tokenizer
import pandas as pd
import collections
from wordcloud import WordCloud
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
t = Tokenizer()
results = []
for s in song_lyrics: result = [token.base_form for token in t.tokenize(s) if token.part_of_speech.split(',')[0] in ['名詞']] results.extend(result)
# 単語の頻度を確認
c = collections.Counter(results)
print(c.most_common())
# wordcloud
# 日本語のフォントパス
fpath = 'C:/Windows/Fonts/YuGothM.ttc'
text = ' '.join(results) # 区切り文字を「・」にして文字列に変換
# 単語の最大表示数は500に設定
wordcloud = WordCloud(background_color='white', font_path=fpath, width=800, height=600, max_words=500).generate(text)
#画像はwordcloud.pyファイルと同じディレクトリにpng保存
wordcloud.to_file('./wordcloud-mrchildren.png')複合名詞化して抽出する
今度は、単語を複合名詞化して抽出してみます。
複合名詞とは、たとえば「形態素」と「解析」という言葉が横並びである場合、「形態素解析」と解析されれば、これは複合名詞になります。
以下が解析結果です。
上記の結果とそれほど変わらないように見えます。

以下がコードです。
importするライブラリが増えているので注意してください。
import pandas as pd
import collections
from wordcloud import WordCloud
from janome.analyzer import Analyzer
from janome.charfilter import *
from janome.tokenfilter import *
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
results = []
for s in song_lyrics: # 複合名詞化 a = Analyzer(token_filters=[CompoundNounFilter()]) result = [token.base_form for token in a.analyze(s) if token.part_of_speech.split(',')[0] in ['名詞']] results.extend(result)
# 単語の頻度を確認
c = collections.Counter(results)
print(c.most_common())
# wordcloud
# 日本語のフォントパス
fpath = 'C:/Windows/Fonts/YuGothM.ttc'
text = ' '.join(results) # 区切り文字を「・」にして文字列に変換
# 単語の最大表示数は500に設定
wordcloud = WordCloud(background_color='white', font_path=fpath, width=800, height=600, max_words=500).generate(text)
#画像はwordcloud.pyファイルと同じディレクトリにpng保存
wordcloud.to_file('./wordcloud-mrchildren.png')意味のわからない単語を除外する
上記の「ん」や「よう」 のような見ても意味のわからない単語はWordCloudで可視化する際に除外します。
かなりわかりやすくなりました。「僕」、「君」、「誰」、「何」などが多いようです。
WordClocdでは、単語の出現頻度がいくらかは具体的にわからないので、グラフ化してみます。
今回はPythonで簡単にグラフ化できるライブラリ「Plotly」を使いました。
グラフ化する単語の条件としては、上記の対象外としたい単語を除外する条件に加え、出現頻度が100回よりも多い単語としました。
下記のグラフの拡大はこちら。(スマホの場合は、画面を横にすると見やすいです。)
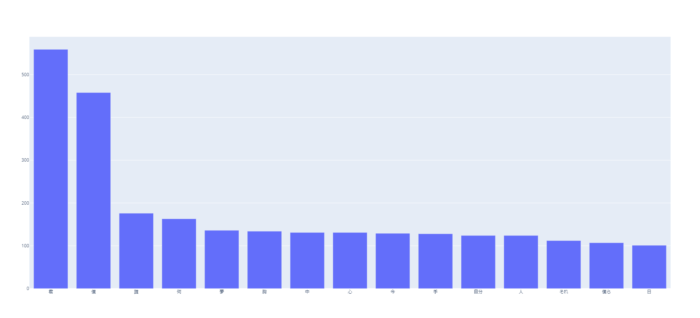
「君」と「僕」が圧倒的に多いことがわかります。
今回のコードは以下です。
import pandas as pd
import collections
from wordcloud import WordCloud
from janome.analyzer import Analyzer
from janome.charfilter import *
from janome.tokenfilter import *
import plotly.graph_objects as go
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
results = []
for s in song_lyrics: # 複合名詞化 a = Analyzer(token_filters=[CompoundNounFilter()]) result = [token.base_form for token in a.analyze(s) if token.part_of_speech.split(',')[0] in ['名詞']] results.extend(result)
# 単語の頻度を確認
c = collections.Counter(results)
print(c.most_common())
# 削除するワードをリスト化
stopwords = ['ん', 'よう', 'の', 'こと', 'さ', 'そう', 'まま', 'はず']
# wordcloud
# 日本語のフォントパス
fpath = 'C:/Windows/Fonts/YuGothM.ttc'
text = ' '.join(results) # 区切り文字を「・」にして文字列に変換
# 単語の最大表示数は500に設定
wordcloud = WordCloud(background_color='white', font_path=fpath, width=800, height=600, max_words=500, stopwords=set(stopwords)).generate(text)
#画像はwordcloud.pyファイルと同じディレクトリにpng保存
wordcloud.to_file('./wordcloud-mrchildren.png')
# グラフ用にデータを抽出
word_ranking = dict(c.most_common())
graph_list = {k:v for k, v in word_ranking.items() if k not in stopwords and v > 100}
# plotlyでグラフ化
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.show()動詞のみ抽出する
上記と同じ手順で動詞のみ抽出した結果は以下です。
動詞の場合は、対象外とする単語を判断するのが難しいですが、例えば、ポジティブな動詞とネガティブな動詞で分けて分析してみると面白そうです。

形容詞のみ抽出する
形容詞のみを抽出した結果は以下です。
形容詞は動詞よりも感情が出てきていそうなので、さらに深く分析すると興味深い結果がでそうです。

今回はJanomeとWordCloudを使ってミスチルの歌詞を分析しました。
普段、何気なく聞いているミスチルの曲ですが、このように普段とは違った視点で見てみるととても面白かったです。
今回は単語の出現頻度のみを解析しましたが、年代別に解析したり、アルバム毎に解析してみるとさらに興味深い結果も出てきそうです。
次は、今回調べて最も多く使われていた「君」と「僕」がどの曲で一番多く使われているのかを調べてみました。
以下にリンクがありますので、興味があれば見てください。
ここまで記事を見ていただき、ありがとうございました!
 ミスチルで一番使われている単語は「君」と「僕」
ミスチルで一番使われている単語は「君」と「僕」