
私はミスチルが20年前から好きで、ある日ふと、歌詞にはどんな単語が多く使われているのだろうと気になりました。
そこでPythonで形態素解析(文章を単語に分けて解析)を行い、一番使われている名詞や動詞、形容詞を確認しました。
確認した方法は、以下の記事に書いているので是非ご参照ください。
 ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた今回は、上記で解析した単語に対して、ネガポジ分析をやってみました。
ネガポジ分析は感情分析という技術の一種で、例えば「嬉しい」=「ポジティブ」、「悲しい」=「ネガティブ」というような判定を行うことができます。
この技術を使用して、ミスチルの歌詞に含まれている単語はポジティブなものが多いのか、ネガティブなものが多いのかを分析してみます。

ネガポジ分析の仕方
極性辞書を使用する
ポジティブ、ネガティブという判定をするには「極性辞書」を使用します。
極性辞書には、ある単語がポジティブか、ネガティブかが収録されています。
日本語の極性辞書としては、以下の2つが有名です。
日本語評価極性辞書は「名詞編」と「用言編」があり、「名詞編」には13,314の名詞が収録されています。
「用言編」には5,280の動詞や形容詞が収録されています。
こちらは商用利用可能で、今回はこちらの極性辞書を利用させていただきます。
単語感情極性対応表は研究目的の利用に限り公開されているので、今回は使用しません。
リソースに「岩波国語辞書(岩波書店)」を使用しており、55,125の単語が含まれています。
また後で説明しますが、日本語極性辞書は単語を「ポジティブ」「ネガティブ」といった分け方をしていますが、単語感情極性対応表は -1.0 を最もネガティブ、 +1.0 を最もポジティブとして -1.0 から +1.0 でネガポジ度を数値化しています。
今回は単語感情極性対応表の分析結果については言及しませんが、こちらの辞書でも分析はしてみました。
結果はQiitaに投稿しています。
分析の流れ
今回の分析の流れとしては、以下のように進めます。
- 歌詞を単語に分解する(形態素解析)
- 分解した単語が極性辞書に含まれているかを確認する
- 辞書に含まれている単語の中で、「ポジティブ」と「ネガティブ」の単語の割合を確認する
簡単な手法でありますが、極性辞書を使う入口としては十分かなと思います。
最終的には曲ごとのネガポジ度を数値化して分析するつもりですが、長くなりそうなので今回は歌詞に使われている単語はポジティブな単語が多いのか、ネガティブな単語が多いのかを確認してみます。
曲ごとの分析は別の記事に記載します。
①に関しては、以下の記事に方法を書いているので参照して下さい。
今回は②から行います。
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた極性辞書をダウンロードする
形態素解析で分解した単語が極性辞書に含まれているかを確認する準備として、まずは極性辞書をダウンロードして中身を把握します。
極性辞書は、東北大学 乾・岡崎研究室のホームページからダウンロードできます。
上記のホームページでは2種類の極性辞書(名詞編・用言編)がダウンロードできます。
今回は両方とも使ってみるので、2つの極性辞書を自分のPCの任意の場所にダウンロードしておきます。
極性辞書の中身を確認する
名詞編(pn.csv.m3.120408.trim)には13,314の名詞が収録されています。以下は名詞編の中身の一部です。

辞書はタブ区切りとなっており、最初が名詞、次が感情(p・e・n)、最後が動詞句となっています。
今回使うのは、最初の名詞と次の感情を使用します。最後の動詞句は使用しません。
感情の内容は以下です。
- p = ポジティブ
- e = ニュートラル(ポジティブ、ネガティブ、どちらとも言えない)
- n = ネガティブ
用言編(wago.121808.pn)には5,280の動詞や形容詞などが収録されています。
以下は用言編の中身の一部です。
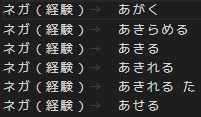

辞書はタブ区切りとなっており、最初が感情、次が用言となっています。
感情の内容は以下です。
- ネガ(経験)
- ネガ(評価)
- ポジ(経験)
- ポジ(評価)
名詞のネガポジ分析を行う
まずは、ミスチルの全歌詞に含まれている名詞のみを使ってネガポジ分析をしてみます。
歌詞に入っている名詞を可視化したものは以下です。

上記のように歌詞から名詞を抽出したり、可視化する方法は以下の記事に書いているのでご参照ください。
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた名詞のネガポジ分析結果
分類対象の全名詞数15,661に対して、分類結果は以下です。
| 分類 | 分類数 | 割合 |
|---|---|---|
| None | 11,358 | 72.8% |
| neutral | 2,107 | 13.5% |
| positive | 1,321 | 8.46% |
| negative | 825 | 5.28% |

positiveの名詞の方がnegativeの名詞よりも多いようです。
ただし、None(辞書に収録されていない名詞)の割合が多いので、辞書への単語の追加、もしくは形態素解析の方法を見直す(単語の分類の仕方を変える)などの対応が必要と思われます。
ポジティブに分類された名詞のうち、使用数が多かった10単語は以下です。
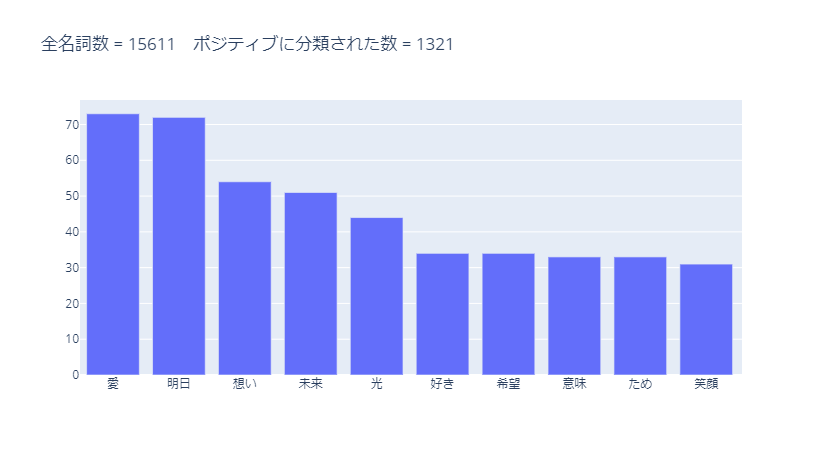
ポジティブな意味で使われそうな単語が多く分類されています。
ただし、「想い」などは文脈によってネガティブな意味になりそうな場合もあると思います。
また、「ため」はここでは意味がわかりません。
あらかじめ、分類対象外にしておいた方が良いです。
ポジティブに分類された全名詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。スマホでは横画面にした方が見やすいと思います。
ネガティブに分類された名詞のうち、使用数が多かった10単語は以下です。
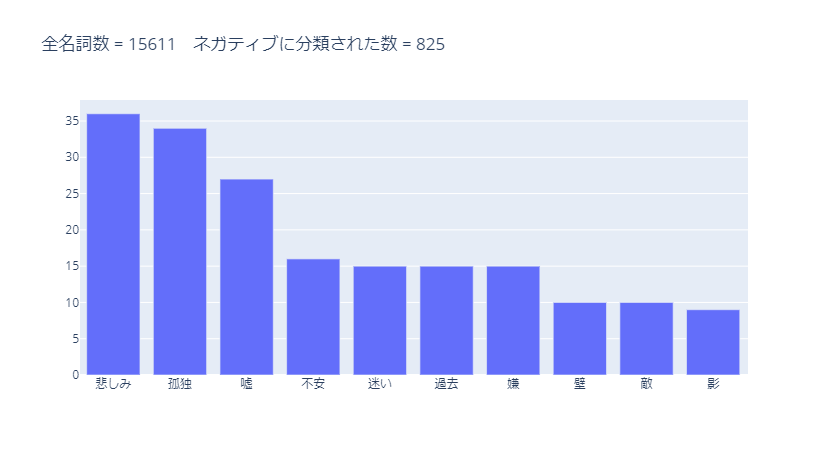
ネガティブな単語が多く分類されています。
ただし、「過去」は必ずしもネガティブな意味ではありません。
ポジティブに分類された言葉の中には「未来」がありましたが、この辺りは状況によって修正が必要になると思います。
ネガティブに分類された全名詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。スマホでは横画面にした方が見やすいと思います。
ニュートラルに分類された名詞のうち、使用数が多かった10単語は以下です。
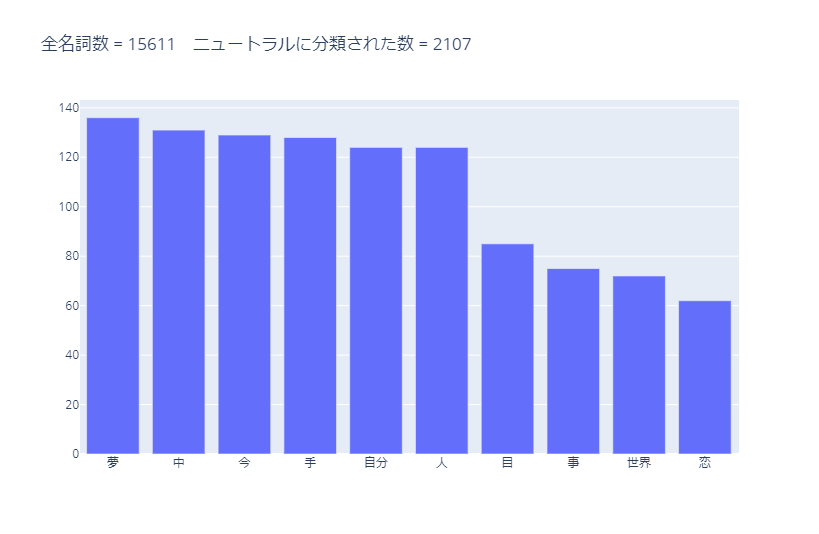
「夢」は文脈によってポジティブかネガティブか判断しないといけないと思うので、ニュートラルで良いと思います。
「恋」はニュートラルに分類されていますが、「愛」はポジティブに分類されています。
この辺りの整合性を取る必要があると思います。
ニュートラルに分類された全名詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。スマホでは横画面にした方が見やすいと思います。
辞書に収録されておらず、分類されなかった名詞のうち、 使用数が多かった10単語は以下です。

ニュートラルに分類されてよいと思う名詞が多くあります。
分類されなかった全名詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。スマホでは横画面にした方が見やすいと思います。
コード
今回、分析に使用したコードを載せておきます。
ポイントとなる部分は後で説明します。
形態素解析を行っているコードも入っているので、そちらについての詳細を知りたい場合は以下の記事を参考にしてください。
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみたimport pandas as pd
import collections
from janome.analyzer import Analyzer
from janome.charfilter import *
from janome.tokenfilter import *
import plotly.graph_objects as go
# カラム名と値の位置ずれを制御
pd.set_option('display.unicode.east_asian_width', True)
# csvファイルを読み込み
df_dic = pd.read_csv('pn.csv.m3.120408.trim', sep='\t', names=("名詞", "感情", "動詞句"), encoding='utf-8')
# 辞書の中身と感情の中身を確認
print(df_dic)
print(df_dic["感情"].value_counts())
# 感情のうち、p/e/nの項目のみを抽出
df_dic = df_dic[(df_dic["感情"] == 'p') | (df_dic["感情"] == 'e') | (df_dic["感情"] == 'n')]
# 動詞句を削除
df_dic = df_dic.iloc[:,0:2]
keys = df_dic["名詞"].tolist()
values = df_dic["感情"].tolist()
dic = dict(zip(keys, values))
# 形態素解析
# 歌詞の名詞のみを読み込む
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
word_list = []
for s in song_lyrics: # 複合名詞化 a = Analyzer(token_filters=[CompoundNounFilter()]) result = [token.base_form for token in a.analyze(s) if token.part_of_speech.split(',')[0] in ['名詞']] word_list.extend(result)
# 削除するワードをリスト化
stopwords = ['ん', 'よう', 'の', 'こと', 'さ', 'そう', 'まま', 'はず']
for stopword in stopwords: word_list = [i for i in word_list if i != stopword]
# 抽出した全名詞数を変数に格納
word_list_num = len(word_list)
# 各名詞が辞書にあるか確認し、あれば感情とともに配列に格納
results = []
for word in word_list: word_score = [] score = dic.get(word) word_score = (word, score) results.append(word_score)
# 結果格納用の配列
None_lists = []
p_lists = []
n_lists = []
e_lists = []
for result in results: if result[1] == 'p': p_lists.append(result[0]) elif result[1] == 'n': n_lists.append(result[0]) elif result[1] == 'e': e_lists.append(result[0]) else: None_lists.append(result[0])
# 円グラフ用にリストを作っておく
pie_list = []
# グラフ用にデータを抽出
x = p_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# graph_list = {k:v for k, v in graph_list.items() if v > 50} グラフに表示するデータの条件を変える場合
# plotlyでグラフ化
graphtitle = "全名詞数 = " + str(word_list_num) + " ポジティブに分類された数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "noun-posi"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# グラフ用にデータを抽出
x = n_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# graph_list = {k:v for k, v in graph_list.items() if v > 50} グラフに表示するデータの条件を変える場合
# plotlyでグラフ化
graphtitle = "全名詞数 = " + str(word_list_num) + " ネガティブに分類された数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "noun-nega"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# グラフ用にデータを抽出
x = e_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# graph_list = {k:v for k, v in graph_list.items() if v > 50} グラフに表示するデータの条件を変える場合
# plotlyでグラフ化
graphtitle = "全名詞数 = " + str(word_list_num) + " ニュートラルに分類された数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "noun-neutral"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# グラフ用にデータを抽出
x = None_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# plotlyでグラフ化
graphtitle = "全名詞数 = " + str(word_list_num) + " 分類されなかった数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "noun-none"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# 円グラフを作成
labels = ['positive','negative','neutral','None']
fig = go.Figure(data=[go.Pie(labels=labels, values=pie_list, pull=[0.2, 0.2, 0, 0])])
fig.update_traces(direction='clockwise')
fig.show()
# グラフをhtml形式で保存。
filename = "noun-pie"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))コードの解説
辞書はタブ区切りになっているので、データフレームとして読み込むときに区切りをタブにしています。
df_dic = pd.read_csv('pn.csv.m3.120408.trim', sep='\t', names=("名詞", "感情", "動詞句"), encoding='utf-8')辞書に入っている感情の内容を確認してみると、以下のようにおかしな判定内容になっている項目も含まれています。
本来であれば、正しく振り分けるのが適切であると思いますが、今回は削除します。
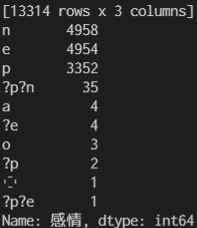
# 辞書の中身と感情の中身を確認
print(df_dic)
print(df_dic["感情"].value_counts())
# 感情のうち、p/e/nの項目のみを抽出
df_dic = df_dic[(df_dic["感情"] == 'p') | (df_dic["感情"] == 'e') | (df_dic["感情"] == 'n')]辞書に入っている動詞句は、今回使用しないので削除します。
# 動詞句を削除
df_dic = df_dic.iloc[:,0:2]# 各名詞が辞書にあるか確認し、あれば感情とともに配列に格納
results = []
for word in word_list: word_score = [] score = dic.get(word) word_score = (word, score) results.append(word_score)動詞のネガポジ分析を行う
続いて、動詞のみを使ってネガポジ分析をしてみます。
歌詞に入っている動詞を可視化したものは以下です。

動詞のネガポジ分析結果
分類対象の全動詞数7,821に対して、以下の結果です。
| 分類 | 分類数 | 割合 |
|---|---|---|
| None | 7,059 | 90.3% |
| positive | 321 | 4.10% |
| negative | 441 | 5.64% |
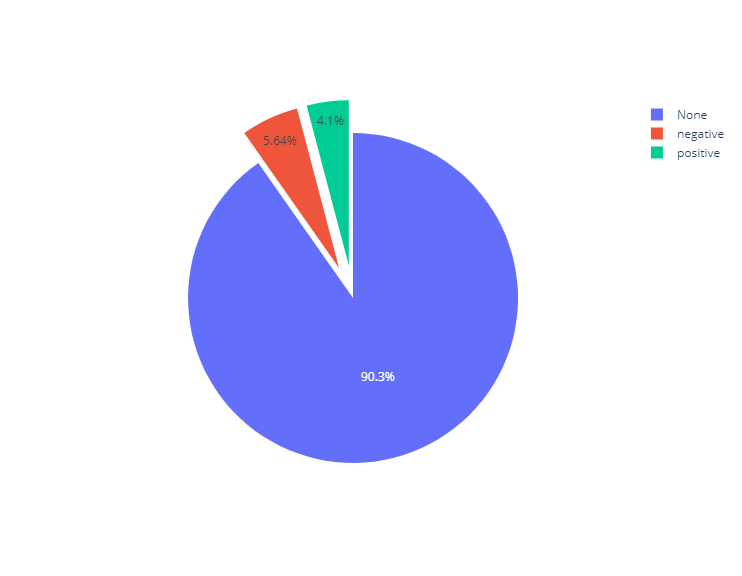
辞書に収録されていない「None」が90%を超えました。
動詞は名詞よりも形が変わりやすいので、完全一致が難しいからではないかと推測します。
形態素解析の方法や辞書の更新が必要であると思います。
ポジティブに分類された動詞のうち、使用数が多かった10単語は以下です。
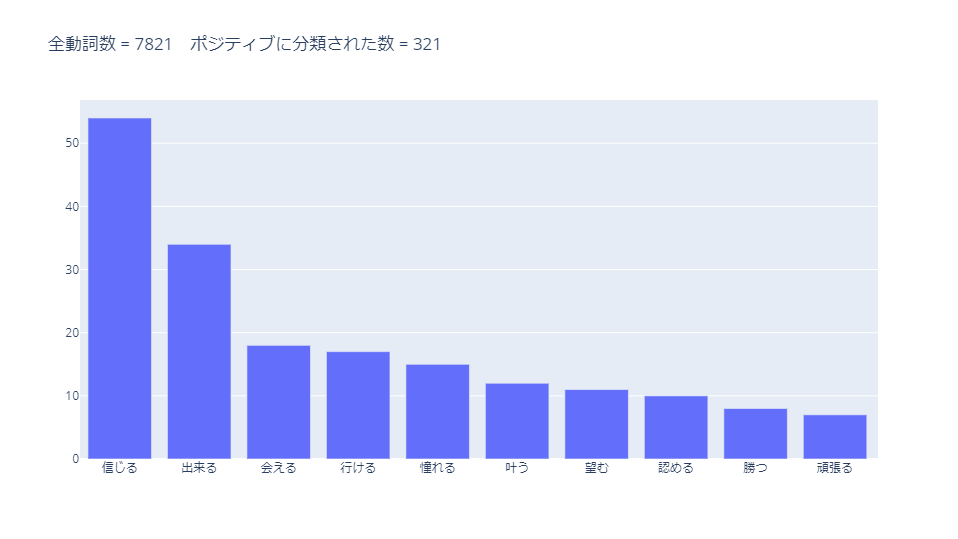
ポジティブな動詞が並んでいます。「~できる」のような可能動詞が多くなっていそうです。
ポジティブに分類された全動詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。スマホでは横画面にした方が見やすいと思います。
ネガティブに分類された動詞のうち、使用数が多かった10単語は以下です。
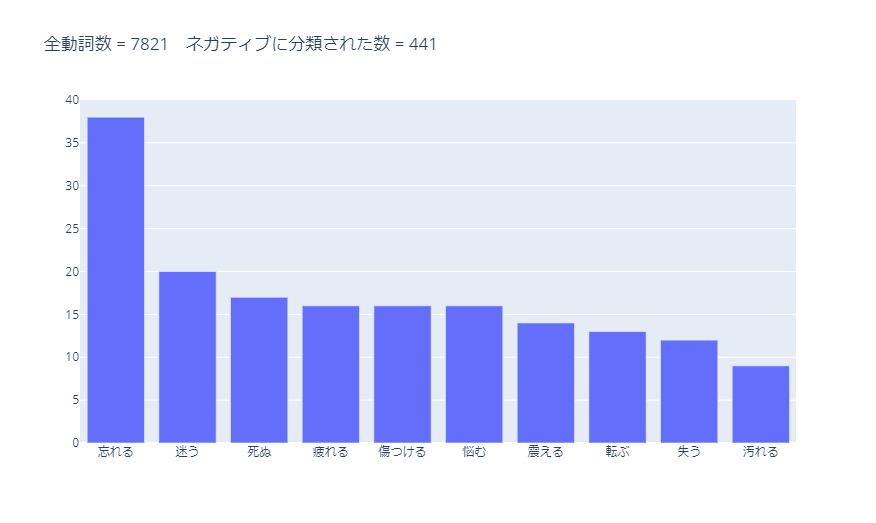
ネガティブな動詞が並んでいます。
ポジティブに分類された全動詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。
スマホでは横画面にした方が見やすいと思います。
辞書に収録されておらず、分類されなかった動詞のうち、使用数が多かった10単語は以下です。
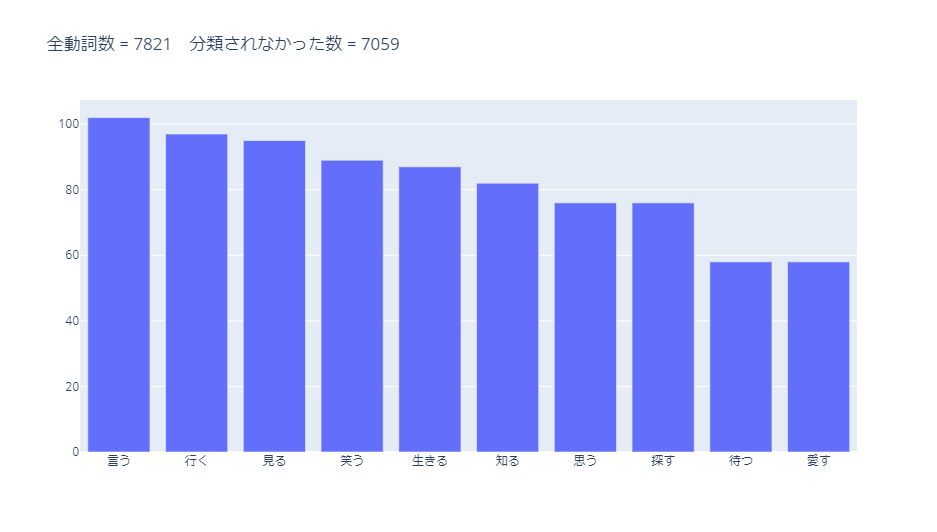
よく使われそうな動詞が多くあります。
分類は難しいと思いますが、辞書の更新が必要と感じます。
分類されなかった全動詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。スマホでは横画面にした方が見やすいと思います。
コード
コードは名詞の場合とほとんど同じです。
若干変更した箇所については、後で説明します。
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた下記のコードでは、名詞のコードと違う箇所をハイライトしています。
from janome.tokenizer import Tokenizer
import pandas as pd
import collections
import plotly.graph_objects as go
# カラム名と値の位置ずれを制御
pd.set_option('display.unicode.east_asian_width', True)
# csvファイルを読み込み
df_dic = pd.read_csv('wago.121808.pn', sep='\t', names=("判定", "用言"), encoding='utf-8')
# ネガ、ポジの表現に変更する
print(df_dic)
print(df_dic["判定"].value_counts())
df_dic["判定"] = df_dic["判定"].str.replace(r"\(.*\)", "", regex=True)
# 用言のスペースを無くしておく
df_dic["用言"] = df_dic["用言"].str.replace(" ", "")
keys = df_dic["用言"].tolist()
values = df_dic["判定"].tolist()
dic = dict(zip(keys, values))
# 歌詞の用言を読み込む
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_lyrics = df_file['歌詞'].tolist()
t = Tokenizer()
word_list = []
for s in song_lyrics: result = [token.base_form for token in t.tokenize(s) if token.part_of_speech.split(',')[0] in ['動詞']] word_list.extend(result)
# 削除するワードをリスト化(動詞)
stopwords = ['合う', 'あう','する', 'てる', 'いる', 'れる', 'なる', 'ある', 'いく', 'くれる', 'くる', 'く', 'られる', 'みる', 'しまう', 'ゆく', 'せる', 'やる']
for stopword in stopwords: word_list = [i for i in word_list if i != stopword]
# 全用言数をカウント
word_list_num = len(word_list)
# 各用言が辞書にあるか確認し、あれば感情とともに配列に格納
results = []
for sentence in word_list: word_score = [] score = dic.get(sentence) word_score = (sentence, score) results.append(word_score)
p_lists = []
n_lists = []
None_lists = []
for result in results: if result[1] == 'ポジ': p_lists.append(result[0]) elif result[1] == 'ネガ': n_lists.append(result[0]) else: None_lists.append(result[0])
# 円グラフ用にリストを作っておく
pie_list = []
# グラフ用にデータを抽出
x = p_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# graph_list = {k:v for k, v in graph_list.items() if v > 50}
# plotlyでグラフ化
graphtitle = "全動詞数 = " + str(word_list_num) + " ポジティブに分類された数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "verb-posi"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# グラフ用にデータを抽出
x = n_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# graph_list = {k:v for k, v in graph_list.items() if v > 50}
# plotlyでグラフ化
graphtitle = "全動詞数 = " + str(word_list_num) + " ネガティブに分類された数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "verb-nega"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# グラフ用にデータを抽出
x = None_lists
c = collections.Counter(x)
graph_list = dict(c.most_common())
# graph_list = {k:v for k, v in graph_list.items() if v > 10}
# plotlyでグラフ化
graphtitle = "全動詞数 = " + str(word_list_num) + " 分類されなかった数 = " + str(len(x))
fig = go.Figure([go.Bar(x=list(graph_list.keys()), y=list(graph_list.values()))])
fig.update_layout(title={'text': graphtitle})
fig.show()
# グラフをhtml形式で保存。
filename = "verb-none"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))
# 円グラフ用のリストに追加
pie_list.append(len(x))
# 円グラフを作成
labels = ['positive','negative', 'None']
fig = go.Figure(data=[go.Pie(labels=labels, values=pie_list, pull=[0.2, 0.2, 0])])
fig.update_traces(direction='clockwise')
fig.show()
# グラフをhtml形式で保存。
filename = "verb-pie"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))コードの解説
用言編は名詞編よりも項目数が少ないので、namesの部分を変えています。
df_dic = pd.read_csv('wago.121808.pn', sep='\t', names=("判定", "用言"), encoding='utf-8')感情は、下記のように4通りになっていますが、ネガとポジの2通りに書き換えます。
- ネガ(経験)
- ネガ(評価)
- ポジ(経験)
- ポジ(評価)
- ネガ
- ポジ
df_dic["判定"] = df_dic["判定"].str.replace(r"\(.*\)", "", regex=True)用言編の辞書では、下記のように用言の中でスペースが入っています。
今回は完全一致を判定条件としているため、スペースを消しておきます。
もっと良い方法はあると思いますが、応急処置的な対応です。
# 用言のスペースを無くしておく
df_dic["用言"] = df_dic["用言"].str.replace(" ", "")名詞の場合と形態素解析の方法を若干変更しています。
詳細については、以下の記事を参考にして下さい。
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた形容詞のネガポジ分析を行う
続いて、形容詞のみを使ってネガポジ分析をしてみます。
歌詞に入っている形容詞を可視化したものは以下です 。

形容詞のネガポジ分析結果
分類対象の全形容詞数1,083に対して、以下の結果です。
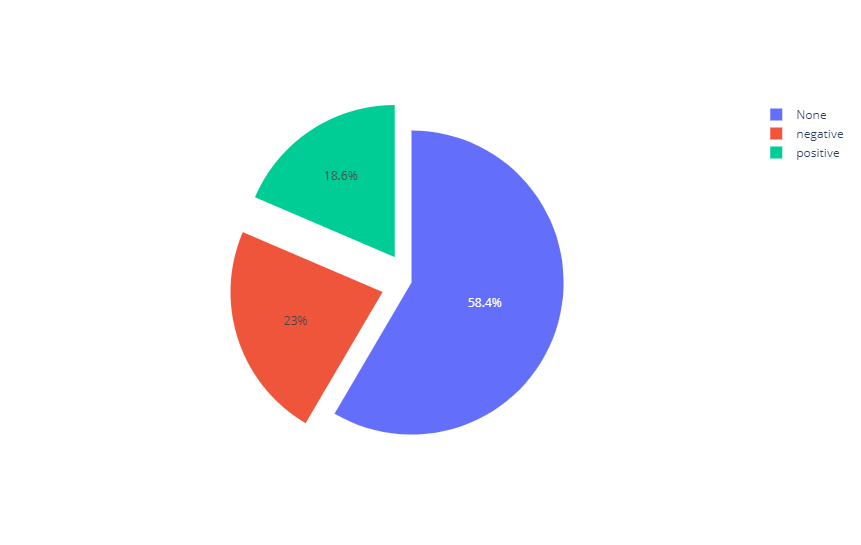
名詞や動詞よりは、ポジティブやネガティブに分類される割合が大きくなっています。
形容詞は気持ちを表すワードが比較的多い気がするので、分類しやすいのかもしれません。
ポジティブに分類された形容詞のうち、使用数が多かった10単語は以下です。
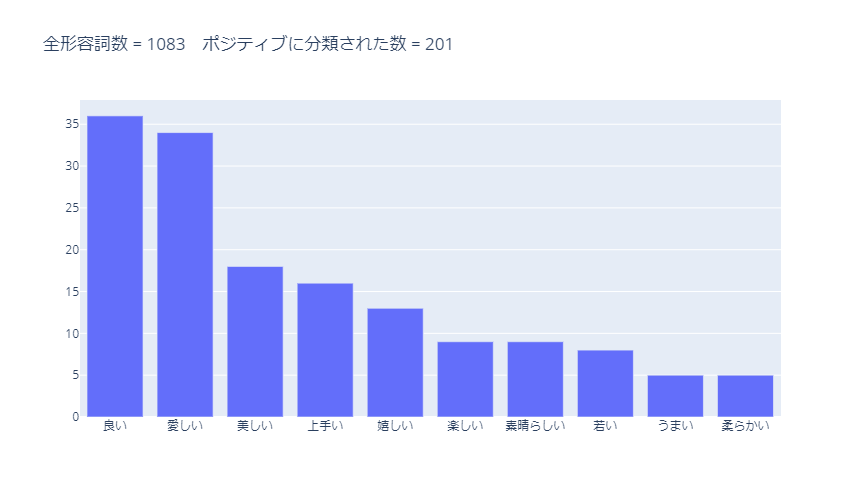
形容詞は明らかにポジティブな単語が多いです。
分類精度が高いと思います。
ただし、「柔らかい」はポジティブではないと思うので、アップデートは必要です。
ポジティブに分類された全形容詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。
スマホでは横画面にした方が見やすいと思います。
ネガティブに分類された形容詞のうち、使用数が多かった10単語は以下です。
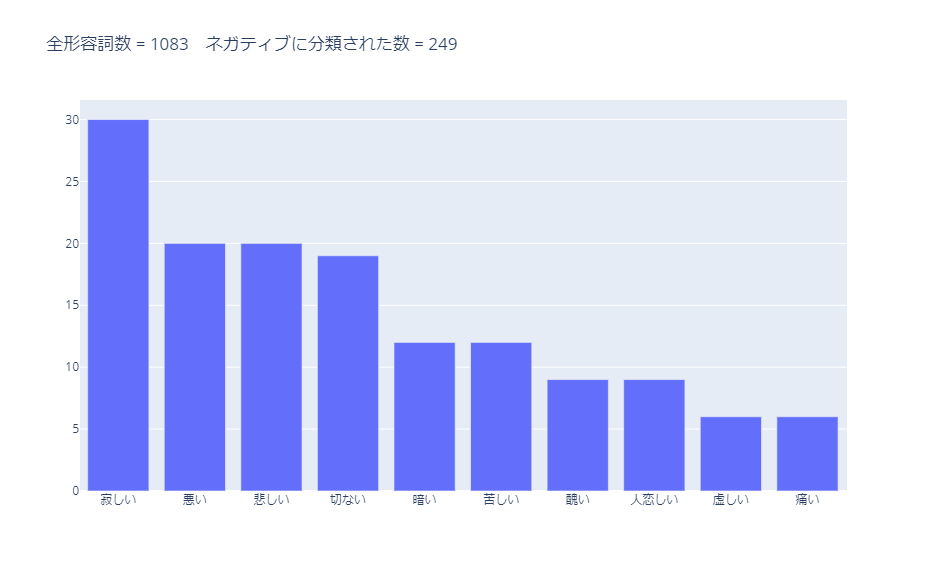
ネガティブに分類された全形容詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。
スマホでは横画面にした方が見やすいと思います。
辞書に収録されておらず、分類されなかった形容詞のうち、 使用数が多かった10単語は以下です。
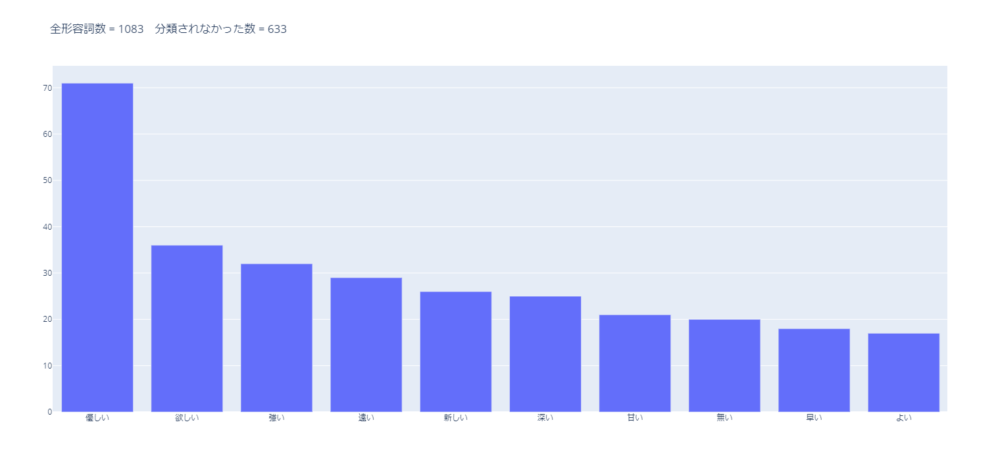
「優しい」はポジティブに分類して良さそうです。
辞書のアップデートは必要と感じます。
分類されなかった全形容詞は、こちらのグラフで確認できます。
拡大や表示範囲の変更ができます。
スマホでは横画面にした方が見やすいと思います。
コード
コードは動詞の場合とほぼ同じです。
変更しているのは以下の2か所のみです。
for s in song_lyrics: result = [token.base_form for token in t.tokenize(s) if token.part_of_speech.split(',')[0] in ['形容詞']]stopwords = ['いい', 'ない', 'くい']参考にした記事
以下の記事を参考にさせていただきました。とても分かりやすかったです。
長くなりましたが、ミスチルの歌詞で使われている単語をネガポジ分析してみました。
今回は単語のみに注目しましたが、次は曲ごとにネガポジ分析を行って、どの曲が一番ポジティブと判定されるのか、どの曲が一番ネガティブと判定されるのかを調べてみました。
 ミスチルで一番ポジティブな曲とネガティブな曲は?【日本語評価極性辞書でネガポジ分析】
ミスチルで一番ポジティブな曲とネガティブな曲は?【日本語評価極性辞書でネガポジ分析】形態素解析やネガポジ分析を行ってみると、改めて日本語がどれだけ複雑で分析が難しいかを感じました。
おそらく、英語などは日本語よりも分析がし易いのだと思います。
ここまで記事を見ていただき、ありがとうございました!

