
私はミスチルが20年前から好きで、ミスチルの歌詞で一番ポジティブな曲とネガティブな曲をPythonを使用して分析してみることにしました。
分析には、「形態素分析」と「日本語評価極性辞典」を使用します。
形態素解析とは、文章を意味のある最小の単語に分割することができる技術です。
形態素解析については、下記の記事で詳しく書いていますので参考にしてください。
 ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた極性辞書は、単語を「ポジティブ」「ネガティブ」などに分類して収録しています。
日本語の極性辞書で有名なのは「日本語評価極性辞書」です。
日本語評価極性辞書は、東北大学 乾・岡崎研究室のホームページで公開されており、クレジットを明記すれば商用利用も可能なので、今回はこちらを利用させていただきます。
極性辞書については、下記の記事で詳しく書いていますので参考にしてください。
ミスチルの歌詞全てを対象に、最も使われているポジティブな単語や、もっとも使われているネガティブな単語を集計してみました。
 ミスチルの歌詞をネガポジ分析してみた【日本語評価極性辞書】
ミスチルの歌詞をネガポジ分析してみた【日本語評価極性辞書】今回は、ミスチルの曲ごとにネガポジ分析を行い、歌詞目線で一番ポジティブな曲とネガティブな曲が何かを分析してみました。

ポジティブな曲ランキング
早速結果ですが、以下がポジティブな曲であると分析した上位10曲です。
| 順位 | 曲名 | スコア |
|---|---|---|
| 1位 | 思春期の夏 ~君との恋が今も牧場に~ | 0.213 |
| 2位 | Drawing | 0.190 |
| 3位 | ありふれた Love Story ~男女問題はいつも面倒だ~ | 0.183 |
| 4位 | himawari | 0.164 |
| 5位 | 放たれる | 0.161 |
| 6位 | Documentary film | 0.158 |
| 6位 | HERO | 0.158 |
| 8位 | 彩り | 0.153 |
| 9位 | 【es】~Theme of es~ | 0.143 |
| 10位 | PADDLE | 0.141 |
ポジティブ!と思っていた曲(個人的にはPADDLE)も入っていますが、ん?と思う曲(Drawing)なども入っています。
スコアの算出方法については、後で説明します。とりあえず上位3曲について詳しく歌詞を見てみます。
1位: 思春期の夏 ~君との恋が今も牧場に~
まさかの曲が1位でした!
この曲はドラムの鈴木英哉(JEN)がボーカルの数少ない曲です(もう1曲は逃亡者)。
作詞は桜井和寿・小林武史、作曲は鈴木英哉・ 小林武史 です。
曲調はポップで、ライブで一度だけ聞いたことがあって(Thanksgiving 25の時)、盛り上がっていたのを覚えています。
歌詞のざっくりした内容は(個人の解釈)、昔の片思い(場所は牧場)を回想しているという内容です。
曲調はポップですが、歌詞はそこまでポジティブというわけではないと思います。
なぜ1位になっているかは後で確認します。
2位: Drawing
こちらは全くポジティブな印象はありません。
私が初めて買ったオリジナルアルバム「IT’S A WONDERFUL WORLD」に収録されている曲で、何回も聞いた曲ですが、曲調は暗めです。
個人的な解釈としては、いつも「君」のことを考えていて永遠に一緒にいたいけど、永遠は無くいつかは終わる、というような儚い歌詞だと思います。
ポジティブではないと思うので、分析ミスと感じます。
3位:ありふれた Love Story ~男女問題はいつも面倒だ~
この曲は曲調が好きで、昔よく聞きました。
ポップな曲です。
歌詞は、都会のビジネスマンと田舎から都会に出たきたばかりの女性が付き合い始めて、一緒に住み始めて、そのうちうまくいかなくなって、別れたという曲です。
最終的に「男女問題っていつも面倒だな」という結論で終わります。ポジティブではないですね。。。
「PADDLE」や「HERO」、「彩り」などかなりポジティブだなと思う曲も入っていますが、ポジティブとはいいがたい曲もいくつか入っています。
分析内容については、後で詳細を説明します。
ネガティブな曲ランキング
続いて、ネガティブな曲であると分析した上位10曲です。
| 順位 | 曲名 | スコア |
|---|---|---|
| 1位 | タダダキアッテ | -0.138 |
| 2位 | Simple | -0.130 |
| 3位 | FIGHT CLUB | -0.127 |
| 4位 | It’s a wonderful world | -0.125 |
| 4位 | Surrender | -0.125 |
| 6位 | 声 | -0.121 |
| 7位 | シーソーゲーム ~勇敢な恋の歌~ | -0.107 |
| 8位 | So Let’s Get Truth | -0.104 |
| 9位 | タガタメ | -0.100 |
| 10位 | マーマレード・キッス | -0.095 |
こちらも上位3曲について詳しく歌詞を見てみます。
1位: タダダキアッテ
タガタメの原曲です。
子供に関する事件に関して、書かれていると思います。
曲調は暗めで、メッセージ性が強い曲なのでネガティブな単語が多く含まれていると思います。
ちなみにタガタメと歌詞は同じです(歌詞の順序は違う所がありますが)。
しかしタガタメは9位です。後で詳細を確認します。
2位: Simple
結婚式で使えるのではと思うくらいの曲です。
曲調は穏やかですが、サビの歌詞はプロポーズのような内容です。
しかし、歌い出しが「マイナス思考」で始まるように、主人公の思考がネガティブに感じる点も多くあります。
3位: FIGHT CLUB
ブラッド・ピットが主人公の映画「ファイトクラブ」に憧れていた過去を回想する歌詞。
ネガティブな単語は多く出てくるかもしれないですが、ネガティブな曲というわけではないと思います。
分析手順
上記の分析結果を出した手順について説明します。
- ミスチルの全歌詞を収集(2021年9月時点)
- 全歌詞を形態素解析で単語に分割
- 分割した単語が極性辞書にあるかを確認。ポジティブ・ネガティブを振り分ける
- 曲ごとにポジティブ・ネガティブの単語の割合を算出しスコア化
①については、スクレイピングで収集しました。
詳細については以下の記事に詳しく書いています。
 ミスチルの歌詞をスクレイピングで取得してみた【Beautiful Soup】
ミスチルの歌詞をスクレイピングで取得してみた【Beautiful Soup】②については、以下の記事で詳しく書いています。
形態素解析で単語を分割した後、WordCloudで頻出単語を画像で表示しています。
下記のような画像です。
 ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた
ミスチルの歌詞をJanomeで解析してWordCloudで可視化してみた③の極性辞書の詳細な内容やいろいろな使い方は下記の記事で詳しく書いています。
ミスチルの歌詞をネガポジ分析してみた【日本語評価極性辞書】今回は、④について詳しく書いていきます。
ただし、①~③についても簡単に説明していきます。
HANABIのネガポジ分析を行ってみる
例として、HANABIのネガポジ分析の流れを説明します。
HANABIを選んだ理由は、「有名」であることと、「説明がしやすそうな分析結果だったから」です。
形態素解析で単語を分割する
まずは、形態素解析で歌詞を単語に分割します。
形態素解析には、Pythonのライブラリ「Janome」を使用しました。
今回は名詞のみを抽出しました。
名詞のみを抽出した理由は、
- 日本語評価極性辞書が「名詞編」と「用言編」に分かれており、「名詞編」の方が単語の収録数が多い。
- 両方の極性辞書を使うのが面倒であった。
- 動詞のみ、形容詞のみでも同じ分析を行ってみたが、形態素解析で分類した単語数が少なく、分析結果がいまいちであった。
ということです。
HANABIを形態素解析し、分類した名詞を抽出すると全部で「89語」となりました。
‘どれ’, ‘値打ち’, ‘僕’, ‘今’, ‘世界’, ‘すべて’, ‘無意味’, ‘手’, ‘もの’, ‘引き換え’, ‘いくつ’, ‘輝き’, ‘平和’, ‘世の中’, ‘理想’, ‘希望’, ‘答えよう’, ‘日常’, ‘君’, ‘柔らか’, ‘笑顔’, ‘僕’, ‘憂鬱’, ‘花火’, ‘光’, ‘一回’, ‘一回’, ‘一回’, ‘一回僕’, ‘手’, ‘誰’, ‘皆’, ‘悲しみ’, ‘素敵’, ‘明日’, ‘臆病風’, ‘波風’, ‘世界’, ‘どれ’, ‘すぎ’, ‘言葉’, ‘自分’, ‘不器用さ’, ‘嫌い’, ‘妙’, ‘器用’, ‘自分’, ‘それ以上’, ‘平等’, ‘時’, ‘未来’, ‘僕ら’, ‘声’, ‘今’, ‘君’, ‘さよなら’, ‘最初’, ‘一回’, ‘一回’, ‘一回’, ‘一回何度’, ‘君’, ‘世界’, ‘想像’, ‘単純’, ‘君’, ‘水’, ‘心’, ‘とき’, ‘分’, ‘とき’, ‘分’, ‘一回’, ‘一回’, ‘一回’, ‘一回君’, ‘誰’, ‘皆’, ‘問題’, ‘素敵’, ‘明日’, ‘臆病風’, ‘波風’, ‘世界’, ‘どれ’, ‘一回’, ‘一回’, ‘一回’, ‘一回’
極性辞書で単語をポジティブ、ネガティブに分類する
上記で抽出した単語が「日本語評価極性辞書(名詞編)」に収録されているか確認します。
日本語評価極性辞書(名詞編)は単語を「p(ポジティブ)」、「n(ネガティブ)」、「e(ニュートラル:どちらとも言い難い)」で分類しています。
もし、単語が収録されていない場合は「None(未収録)」として記録しておきます。
上記で分類した名詞の中で、ポジティブに分類されたのは下記の「14語」です。
‘値打ち’, ‘輝き’, ‘平和’, ‘理想’, ‘希望’, ‘笑顔’, ‘光’, ‘素敵’, ‘明日’, ‘器用’, ‘平等’, ‘未来’, ‘素敵’, ‘明日’
ネガティブに分類されたのは下記の「7語」です。
‘無意味’, ‘憂鬱’, ‘悲しみ’, ‘波風’, ‘嫌い’, ‘問題’, ‘波風’
ニュートラルに分類されたのは下記の「14語」です。
‘今’, ‘世界’, ‘手’, ‘手’, ‘皆’, ‘世界’, ‘自分’, ‘妙’, ‘自分’, ‘今’, ‘世界’, ‘単純’, ‘皆’, ‘世界’
辞書に未収録で分類できなかったのは、残りの「54語」となりました。
ポジティブ度、ネガティブ度をスコア化する
上記で分類した単語数からスコアを算出します。
スコアは2種類算出します。
- 未分類の単語を含まないスコア1
- 未分類の単語を含むスコア2
未分類の単語を含んで計算する場合と含まずに計算する場合の違いを確認します。
未分類の単語を含まないスコアは下記のように計算しました。
$$score1 \ = \ pの割合 \ – \ nの割合$$
$$pの割合 \ = \ \frac{pの単語数}{ (pの単語数 \ + \ nの単語数 \ + \ eの単語数)}$$
$$nの割合 \ = \frac{ nの単語数 }{ (pの単語数 \ + \ nの単語数 \ + \ eの単語数) } $$
$$p:ポジティブに分類された単語$$
$$n:ネガティブに分類された単語$$
$$e:ニュートラルに分類された単語$$
$$score1: -1 \leq score1 \leq1$$
$$pの割合:0 \leq p \leq1$$
$$nの割合:0 \leq n \leq1$$
スコア1は 1 に近いほどポジティブ、-1 に近いほどネガティブです。
HANABIのスコア1は下記のようになります。
若干ポジティブよりではありますが、ほぼニュートラルです。
\begin{align} score1 &= \frac{14}{14 \ + \ 7 \ + \ 14} \ – \frac{7}{14 \ + \ 7 \ + \ 14} \\[10px] &= 0.200 \end{align}
未分類の単語を含むスコアは下記のように計算しました。
$$score2 \ = \ pの割合 \ – \ nの割合$$
$$pの割合 \ = \frac{pの単語数}{ (pの単語数 \ + \ nの単語数 \ + \ eの単語数 + \ 未分類の単語数)}$$
$$= \ \frac{pの単語数}{全単語数} $$
$$nの割合 \ = \frac{nの単語数}{ (pの単語数 \ + \ nの単語数 \ + \ eの単語数 + \ 未分類の単語数)}$$
$$= \ \frac{nの単語数}{全単語数} $$
$$p:ポジティブに分類された単語$$
$$n:ネガティブに分類された単語$$
$$e:ニュートラルに分類された単語$$
$$score2: -1 \leq score1 \leq1$$
$$pの割合:0 \leq p \leq1$$
$$nの割合:0 \leq n \leq1$$
スコア2もスコア1同様、 1 に近いほどポジティブ、-1 に近いほどネガティブです。
HANABIのスコア2は下記のようになります。
先ほどよりもスコアが0に近づきました。
未分類が多いほど、スコアが0に近づいてしまいます。
\begin{align} score2 &= \frac{14}{89} \ – \frac{7}{89} \\[10px] &= 0.079 \end{align}
ちなみに上記のランキングは、スコア2を使っています。理由は後で説明します。
全曲のネガポジ度を確認する
各曲に含まれている「ポジティブ」、「ネガティブ」、「ニュートラル」、「未分類」の個数と、上記の方法で2つのスコアを算出した結果を表したのが以下のグラフです。
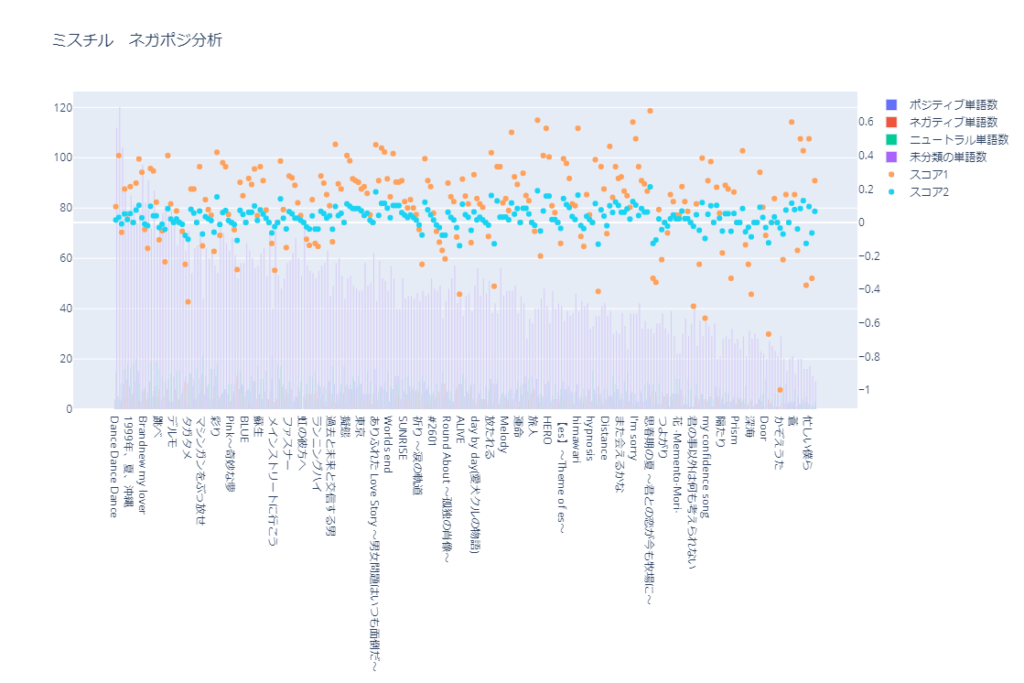
上記では見にくいので、各項目を見ていきます。
上記のグラフはこちらで詳しく見ることができます。
項目を一つずつ確認したり、表示範囲を変更したりできます。
スマホの場合は横画面の方が見やすいです。
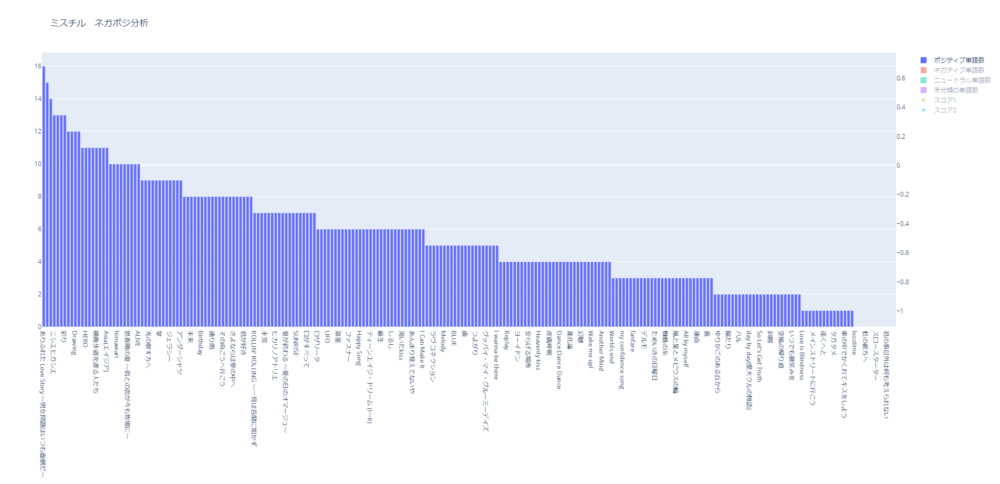
ポジティブな単語数
ポジティブな単語数を多い順に並べたグラフです。
上位10曲は以下です。
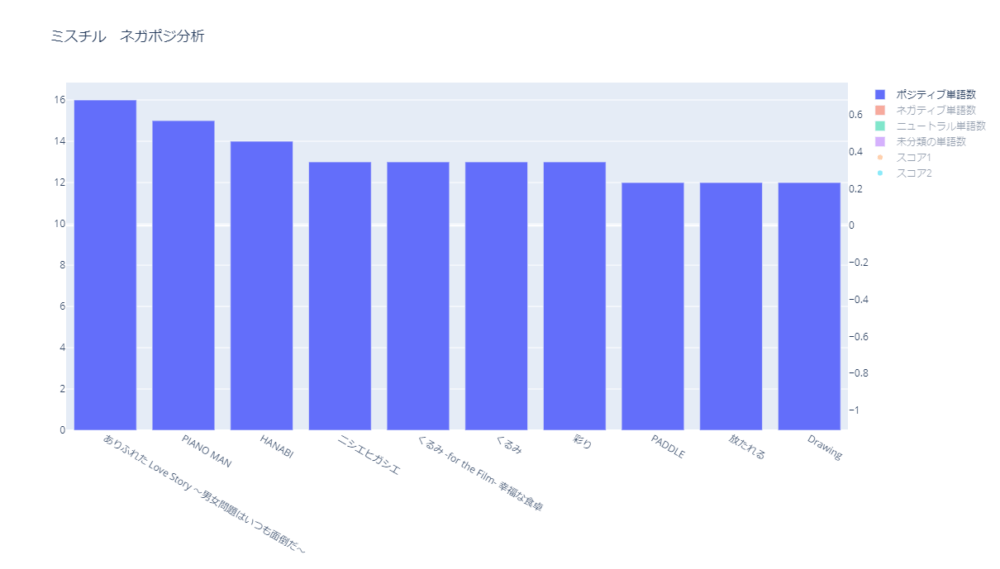
| 順位 | 曲名 | ポジティブ 単語数 | ネガティブ 単語数 | スコア2 | スコア2での順位 (ポジティブ順) |
|---|---|---|---|---|---|
| 1位 | ありふれた Love Story ~男女問題はいつも面倒だ~ | 16 | 3 | 0.183 | 3位 |
| 2位 | PIANO MAN | 15 | 4 | 0.103 | 26位 |
| 3位 | HANABI | 14 | 7 | 0.079 | 53位 |
| 4位 | 彩り | 13 | 0 | 0.153 | 8位 |
| 4位 | くるみ | 13 | 6 | 0.101 | 29位 |
| 4位 | くるみ -for the Film- 幸福な食卓 | 13 | 6 | 0.101 | 29位 |
| 4位 | ニシエヒガシエ | 13 | 8 | 0.085 | 42位 |
| 8位 | I’LL BE | 12 | 10 | 0.018 | 144位 |
| 8位 | Drawing | 12 | 1 | 0.190 | 2位 |
| 8位 | 放たれる | 12 | 2 | 0.161 | 5位 |
| 20位 | 思春期の夏 ~君との恋が今も牧場に~ | 10 | 0 | 0.213 | 1位 |
ポジティブな単語数が多かったとしても、ネガティブな単語数が多いとスコアは下がります。
また、単純に歌詞の中に単語数が多い方がポジティブな単語数で比べると上位になります。
ポジティブなスコアで1位の「 思春期の夏 ~君との恋が今も牧場に~」は、ポジティブな単語数は比較的多くないですが、ネガティブな単語が含まれていないためスコアで1位になっています。
ネガティブな単語数
ネガティブな単語数を多い順に並べたグラフです。
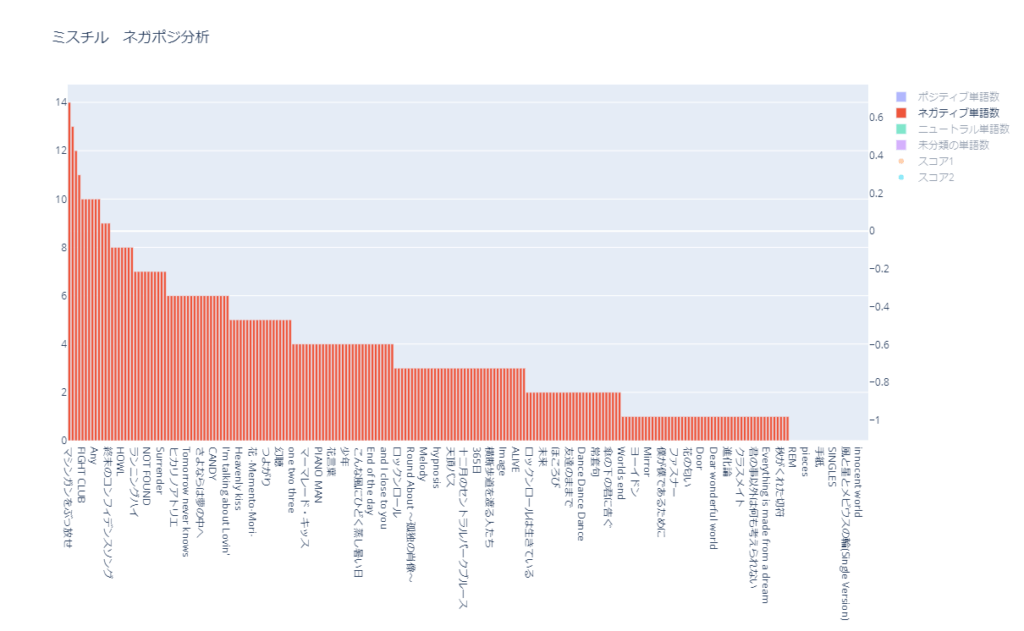
上位10曲は以下です。
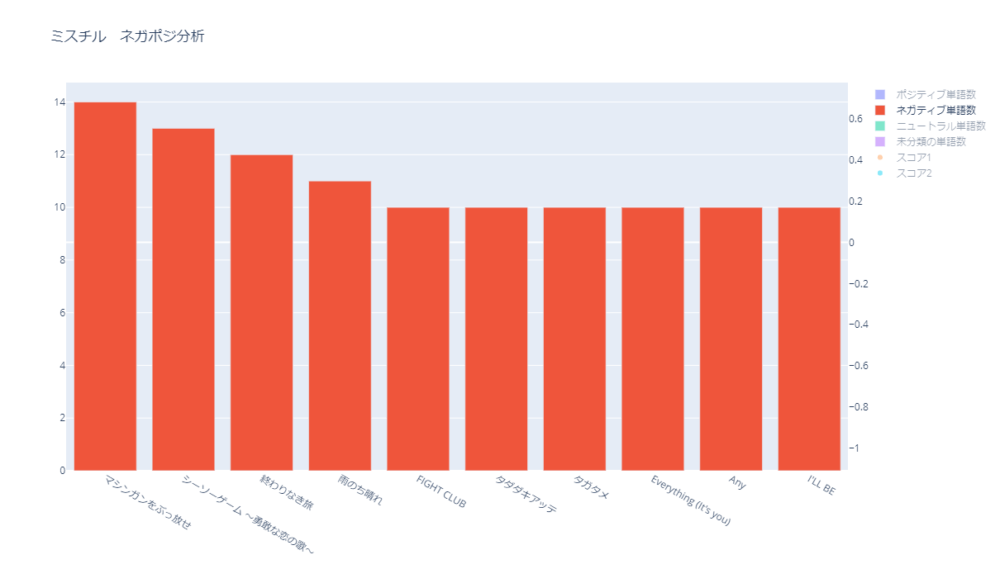
| 順位 | 曲名 | ネガティブ 単語数 | ポジティブ 単語数 | スコア2 | スコア2での順位 (ネガティブ順) |
|---|---|---|---|---|---|
| 1位 | マシンガンをぶっ放せ | 14 | 8 | -0.069 | 16位 |
| 2位 | シーソーゲーム ~勇敢な恋の歌~ | 13 | 4 | -0.107 | 7位 |
| 3位 | 終わりなき旅 | 12 | 7 | -0.063 | 18位 |
| 4位 | 雨のち晴れ | 11 | 4 | -0.077 | 12位 |
| 5位 | I’LL BE | 10 | 12 | 0.018 | 98位 |
| 5位 | Any | 10 | 5 | -0.076 | 13位 |
| 5位 | Everything (It’s you) | 10 | 5 | -0.076 | 13位 |
| 5位 | FIGHT CLUB | 10 | 2 | -0.123 | 3位 |
| 5位 | タガタメ | 10 | 1 | -0.100 | 9位 |
| 5位 | タダダキアッテ | 10 | 1 | -0.138 | 1位 |
| 11位 | Simple | 9 | 2 | -0.130 | 2位 |
「タガタメ」と「タダダキアッテ」は「ネガティブ」と「ポジティブ」の単語数が同じなのでスコア2が違うのは、「未分類の単語数」が「タガタメ」の方が多いからです。
‘どれ’, ‘値打ち’, ‘僕’, ‘今’, ‘世界’, ‘すべて’, ‘無意味’, ‘手’, ‘もの’, ‘引き換え’, ‘いくつ’, ‘輝き’, ‘平和’, ‘世の中’, ‘理想’, ‘希望’, ‘[‘ディカプリオ’, ‘出世作’, ‘さっき僕’, ‘録画’, ‘話’, ‘星’, ‘君’, ‘僕’, ‘あと何人’, ‘人’, ‘人’, ‘キス’, ‘子供ら’, ‘被害者’, ‘加害者’, ‘街’, ‘何’, ‘?’, ‘被害者’, ‘加害者’, ‘とき’, ‘涙’, ‘瞼’, ‘ほか’, ‘?タダタダダキアッテ\u3000(‘, ‘)カタタタキダキアッテ\u3000(肩叩き’, ‘)テヲトッテダキアッテ\u3000(手’, ‘)左’, ‘人’, ‘右’, ‘人’, ‘場所’, ‘片一方’, ‘僕ら’, ‘連鎖’, ‘生き物’, ‘世界’, ‘怒り’, ‘悲しみ’, ‘あと何度’, ‘それ’, ‘?明日’, ‘公園’, ‘手’, ‘犬’, ‘何’, ‘タタカッテ’, ‘タタカッテ\u3000(‘, ‘)タガタメ’, ‘タタカッテ\u3000(誰’, ‘)タタカッテ’, ‘ダレ’, ‘カッタ\u3000(‘, ‘誰’, ‘?)タガタメダ’, ‘タガタメダ\u3000(誰’, ‘?\u3000誰’, ‘?)タガタメ’, ‘タタカッタ\u3000(誰’, ‘?)子供ら’, ‘被害者’, ‘加害者’, ‘街’, ‘何’, ‘?’, ‘被害者’, ‘加害者’, ‘とき’, ‘性懲り’, ‘こと以外’, ‘タダタダダキアッテ\u3000(‘, ‘)カタタタキダキアッテ\u3000(肩叩き’, ‘)テヲトッテダキアッテ\u3000(手’, ‘)タダタダタダ\u3000(‘, ‘)タダタダタダ\u3000(‘, ‘)タダタダキアッテイコウ\u3000(ただ’, ‘)タタカッテ’, ‘タタカッテ\u3000(‘, ‘)タガタメ’, ‘タタカッテ\u3000(誰’, ‘)タタカッテ’, ‘ダレ’, ‘カッタ\u3000(‘, ‘誰’, ‘?)タガタメダ’, ‘タガタメダ\u3000(誰’, ‘?\u3000誰’, ‘?)タガタメ’, ‘タタカッタ\u3000(誰’, ‘?)’
‘ディカプリオ’, ‘出世作’, ‘さっき僕’, ‘録画’, ‘話’, ‘星’, ‘君’, ‘僕’, ‘あと何人’, ‘人’, ‘人’, ‘キス’, ‘世界’, ‘怒り’, ‘悲しみ’, ‘あと何度’, ‘それ’, ‘?明日’, ‘公園’, ‘手’, ‘犬’, ‘何’, ‘左’, ‘人’, ‘右’, ‘人’, ‘場所’, ‘片一方’, ‘僕ら’, ‘連鎖’, ‘生き物’, ‘子供ら’, ‘被害者’, ‘加害者’, ‘街’, ‘何’, ‘?’, ‘被害者’, ‘加害者’, ‘とき’, ‘涙’, ‘瞼’, ‘ほか’, ‘?’, ‘肩叩き’, ‘手’, ‘子供ら’, ‘被害者’, ‘加害者’, ‘街’, ‘何’, ‘?’, ‘被害者’, ‘加害者’, ‘とき’, ‘性懲り’, ‘こと以外’, ‘肩叩き’, ‘手’, ‘誰’, ‘誰’, ‘?誰’, ‘?\u3000誰’, ‘?誰’, ‘?’
「タガタメ」の方が「タタカッテ」などのカタカナが多く入っています。
辞書にこれらのカタカナは入っていないので、Noneの分類結果が多くなっています。
「タダダキアッテ」の方は、上記のカタカナ部分はひらがなで歌詞に記載されています。
ひらがなの「ただ」は、分析に含まないように前処理していたので、このような差が出ています。
また、「\u3000」(全角スペース)が多く含まれているせいで分析が上手くいっていない部分もあると思います。
前処理で消しておかないといけませんでした。
スコア1( 未分類の単語を含まない )
スコア1( 未分類の単語を含まない )をスコアが高い順に並べたグラフです。
スコアは第2軸(右側)です。
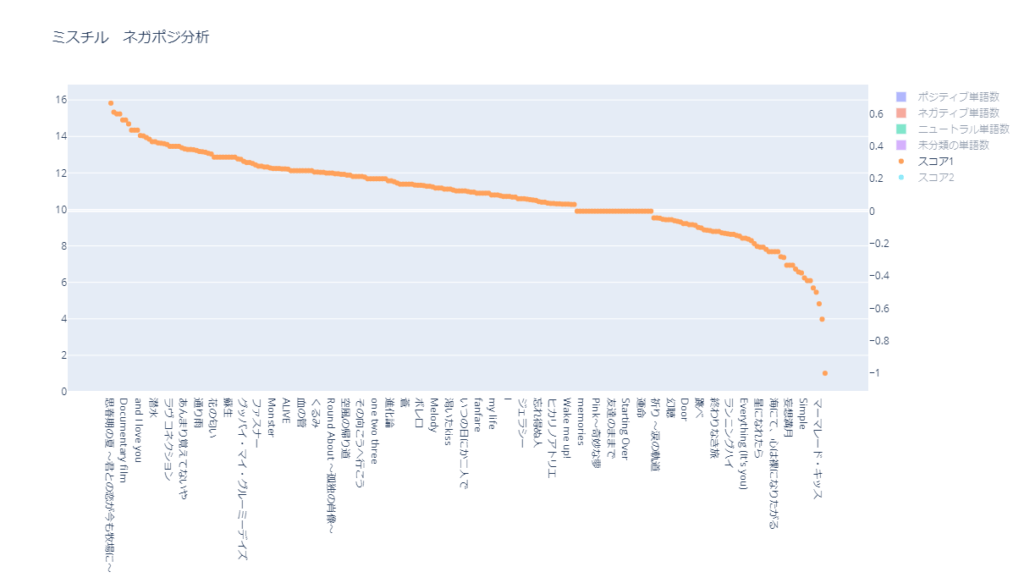
ポジティブな上位10曲を確認します。
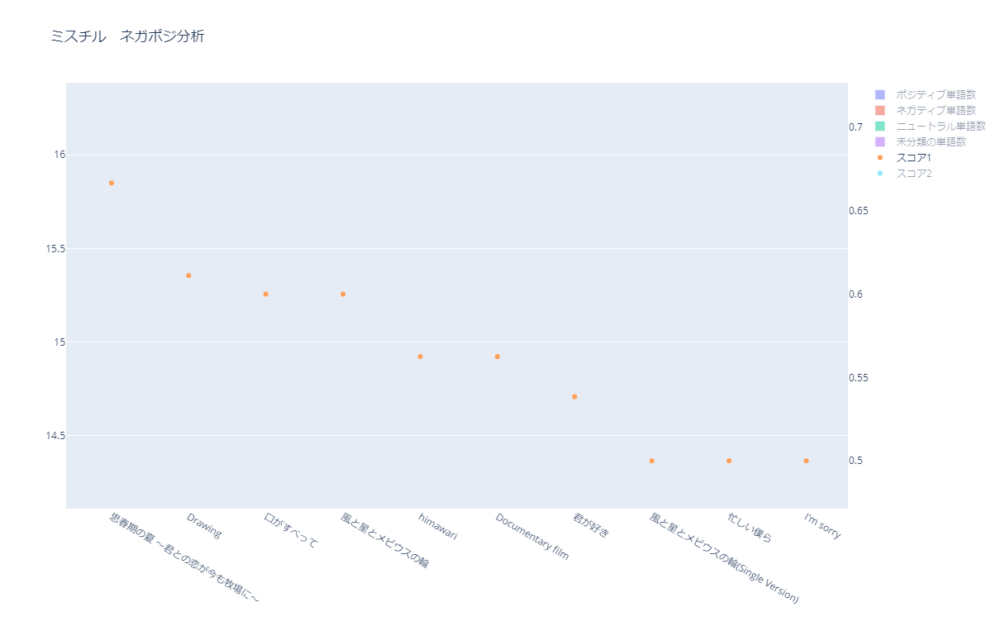
| 曲名 | スコア1 | スコア1順位 (ポジティブ順) | スコア2 | スコア2順位 (ポジティブ 順) | 未分類単語数 | 未分類単語割合 |
|---|---|---|---|---|---|---|
| 思春期の夏 ~君との恋が今も牧場に~ | 0.667 | 1位 | 0.213 | 1位 | 32 | 68.1% |
| Drawing | 0.611 | 2位 | 0.190 | 2位 | 40 | 69.0% |
| 口がすべって | 0.600 | 3位 | 0.125 | 13位 | 38 | 79.2% |
| 風と星とメビウスの輪 | 0.600 | 3位 | 0.115 | 18位 | 21 | 80.8% |
| Documentary film | 0.563 | 5位 | 0.158 | 6位 | 41 | 71.2% |
| himawari | 0.563 | 5位 | 0.163 | 4位 | 39 | 70.9% |
| 君が好き | 0.538 | 7位 | 0.117 | 17位 | 47 | 78.3% |
| I’m sorry | 0.500 | 8位 | 0.104 | 25位 | 38 | 79.2% |
| 忙しい僕ら | 0.500 | 8位 | 0.095 | 38位 | 17 | 81.0% |
| 風と星とメビウスの輪(Single Version) | 0.500 | 8位 | 0.083 | 44位 | 20 | 83.3% |
「風と星とメビウスの輪(Single Version)」を確認してみると、スコア1が8位に対して、スコア2が44位になっています。
未分類の単語の割合を見てみると83.3%もあります。
逆に考えると、分類には16.7%しか使えていないということです。
”君’, ‘僕’, ‘メビウス’, ‘輪’, ‘上’, ‘時流(とき)’, ‘一歩’, ‘心’, ‘風’, ‘唄’, ‘心’, ‘一歩’, ‘心’, ‘星’, ‘頼り’, ‘君’, ‘僕’, ‘メビウス’, ‘輪’, ‘上’
今回の分類全体で、未分類の単語の割合は73.0%です。
つまり、全体の27.0%しか分類に使えていないということになります。
分類精度を上げるには、辞書を更新して未分類の単語を減らさないといけません。
ネガティブな上位10曲を確認します。
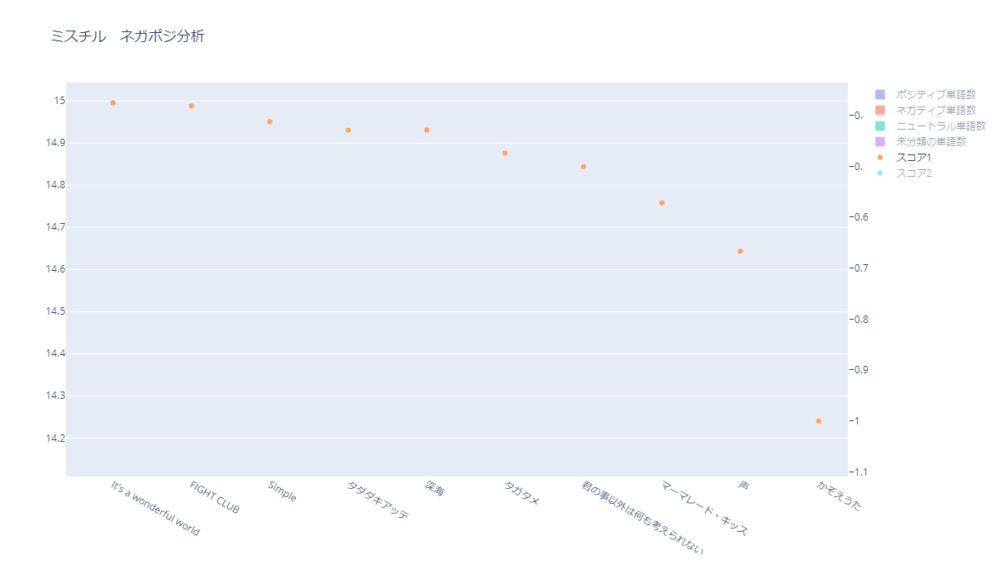
| 曲名 | スコア1 | スコア1順位 (ネガティブ順) | スコア2 | スコア2順位 ( ネガティブ 順) | 未分類単語数 | 未分類単語割合 |
|---|---|---|---|---|---|---|
| かぞえうた | -1.000 | 1位 | -0.033 | 37位 | 29 | 96.7% |
| 声 | -0.667 | 2位 | -0.121 | 6位 | 27 | 81.8% |
| マーマレード・キッス | -0.571 | 3位 | -0.095 | 10位 | 35 | 83.3% |
| 君の事以外は何も考えられない | -0.500 | 4位 | -0.023 | 45位 | 42 | 95.4% |
| タガタメ | -0.474 | 5位 | -0.100 | 9位 | 71 | 78.9% |
| 深海 | -0.429 | 6位 | -0.086 | 11位 | 28 | 80.0% |
| タダダキアッテ | -0.429 | 6位 | -0.138 | 1位 | 44 | 67.7% |
| Simple | -0.412 | 8位 | -0.130 | 2位 | 37 | 68.5% |
| FIGHT CLUB | -0.381 | 9位 | -0.127 | 3位 | 42 | 66.7% |
| It’s a wonderful world | -0.375 | 10位 | -0.125 | 4位 | 16 | 66.7% |
「かぞえうた」を見てみると、スコア1が-1.000になっています。
つまり、分類済みの全単語がネガティブな単語という分析結果です。
ただし、未分類の単語の割合は96.7%になっており、ほとんど分類できていません。
‘うた’, ‘なに’, ‘なに’, ‘やみ’, ‘ひとつふたつ’, ‘ひとつ’, ‘こころ’, ‘あなた’, ‘なん’, ‘かなしみ’, ‘ひとつふたつ’, ‘ひとつ’, ‘ぼう’, ‘うた’, ‘むりなんかしなくてもひとりふたりもうひとりと’, ‘いつか’, ‘ょにうたいたいなえがおのうた僕ら’, ‘以上’, ‘風’, ‘稲穂’, ‘なに’, ‘ひとつふたつ’, ‘ひとつ’, ‘あなた’, ‘ぼう’, ‘うたひとつふたつ’, ‘ひとつ’, ‘びににたきえない’, ‘ぼう’, ‘うた’
このうち、分類できたのは「かなしみ」のみで、ネガティブに分類されています。
このように、歌詞がほとんど平仮名では正常に分析できていないので、辞書にフリガナを追加するなどの対処が必要かもしれません。
スコア2( 未分類の単語を含む)
上記ような問題があるため、今回はスコア2を最終的な分析結果としました。
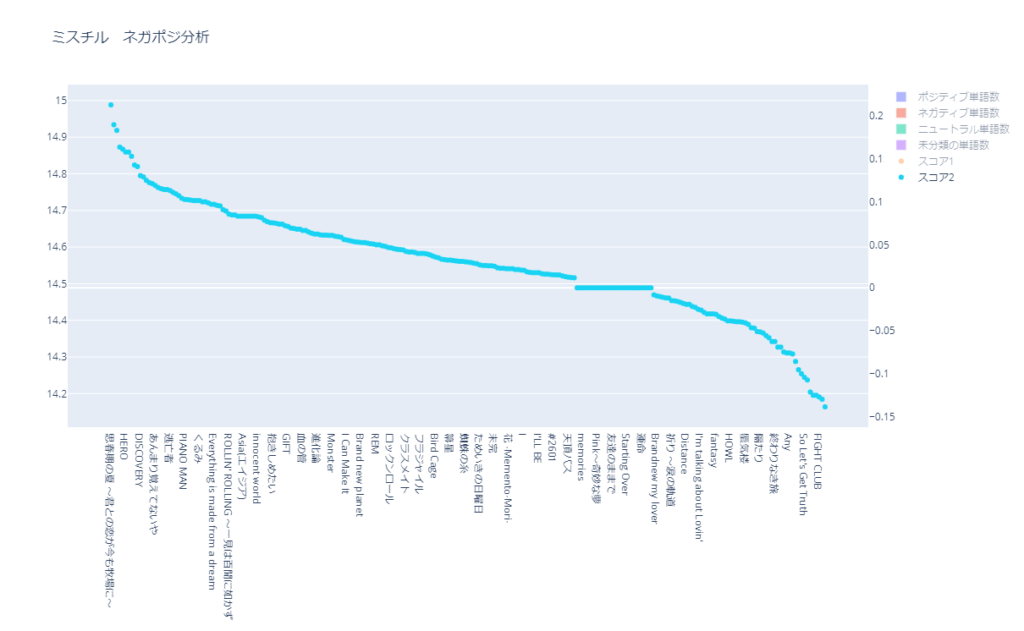
上位10件については、記事冒頭に示しています。
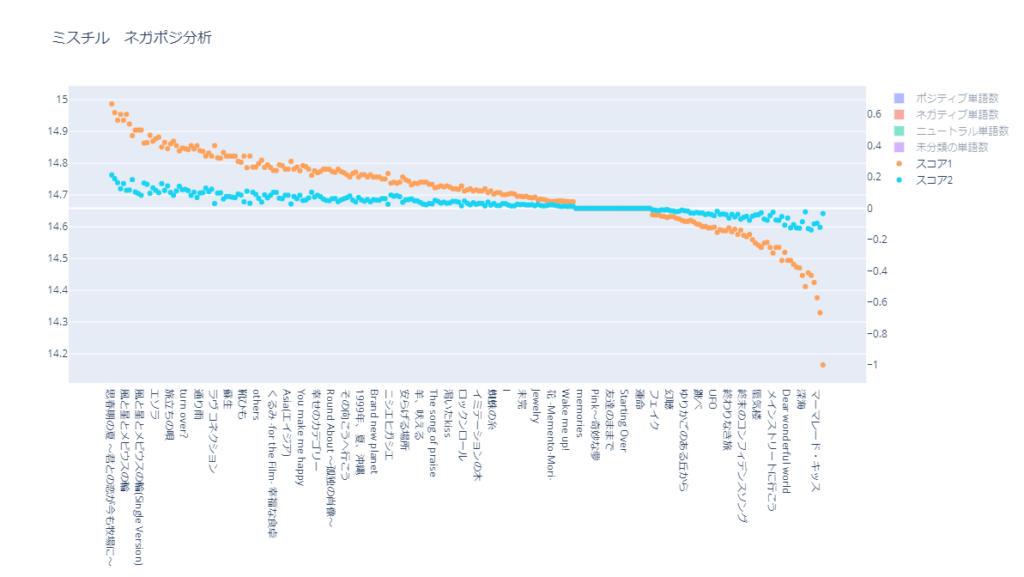
以下が、スコア1とスコア2を比較したグラフです。
未分類が多いので、スコア2は全体的に0に近づいています。
分析の課題
今回分析を行って、歌詞のネガポジ度を数値化することで曲の特徴をいつもとは違った視点でわかりやすく示すことができたと思います。
曲調でポジティブな印象を持っていても、歌詞を見てみると案外ネガティブな内容だったということもありました。
しかし、分類精度が低いので精度を上げるためには以下のような対応が必要であると考えます。
- 形態素解析の精度を上げる
- 極性辞書を分析対象に合わせて自作・更新する(ネガポジの精度向上・未分類率の低下)
上記のような課題があると思いますが、日本語は本当に複雑で、同じような言葉が少し変わるだけで全く違う意味になったり、同じ意味でもいくつもの形があったりと、大変分析が難しいです。
極性辞書を使用する他の方法で、Googleの「Natural Cloud Language API」を使用する方法があります。
こちらはとても簡単にネガポジ分析ができるので、お手軽でおすすめです。
ミスチルの「終わりなき旅」を 「Natural Cloud Language API」 で分析してみた結果を以下の記事に書いているので、気になる方は見てください。
 ミスチルの終わりなき旅をCloud Natural Language APIで感情分析してみた
ミスチルの終わりなき旅をCloud Natural Language APIで感情分析してみたコード
最後に、今回作成したコードを載せておきます。
使用しているライブラリの説明や、歌詞データの内容については冒頭に載せた関連記事に記載している内容と同じです。
import pandas as pd
import collections
from janome.analyzer import Analyzer
from janome.charfilter import *
from janome.tokenfilter import *
import plotly.graph_objects as go
# カラム名と値の位置ずれを制御
pd.set_option('display.unicode.east_asian_width', True)
# csvファイルを読み込み
df_dic = pd.read_csv('pn.csv.m3.120408.trim', sep='\t', names=("名詞", "判定", "詳細"), encoding='utf-8')
# p,n,eの判定値の項目のみ取り出し
df_dic = df_dic[(df_dic["判定"] == 'p') | (df_dic["判定"] == 'e') | (df_dic["判定"] == 'n')]
# 名詞と判定値のみ取り出し
df_dic = df_dic.iloc[:,0:2]
keys = df_dic["名詞"].tolist()
values = df_dic["判定"].tolist()
dic = dict(zip(keys, values))
# 歌詞の名詞を読み込む
# csvファイルを読み込み
df_file = pd.read_csv('mrchildren-lyrics.csv', encoding='utf-8')
# 歌詞をデータフレームからリストに変換
song_info = df_file[["曲名", "歌詞"]]
song_list = []
for song_name, song_lyrics in zip(song_info['曲名'], song_info['歌詞']): # 複合名詞化 a = Analyzer(token_filters=[CompoundNounFilter()]) result = [token.base_form for token in a.analyze(song_lyrics) if token.part_of_speech.split(',')[0] in ['名詞']] result_list = [song_name, result] song_list.append(result_list)
# 削除するワードをリスト化
stopwords = ['ん', 'よう', 'の', 'こと', 'さ', 'そう', 'まま', 'はず', 'ため']
for song in song_list: for stopword in stopwords: song[1] = [i for i in song[1] if i != stopword] song_word_num = len(song[1]) song.append(song_word_num) # 辞書で判定 results = [] for sentence in song[1]: word_score = [] score = dic.get(sentence) word_score = (sentence, score) results.append(word_score) # 判定を曲情報に追加 song.append(results) # それぞれの曲の単語をp,n,e,Noneに分けてリストに格納 p_lists = [] n_lists = [] e_lists = [] None_lists = [] for result in results: if result[1] == 'p': p_lists.append(result[0]) elif result[1] == 'n': n_lists.append(result[0]) elif result[1] == 'e': e_lists.append(result[0]) else: None_lists.append(result[0]) # それぞれのリストを曲情報に追加 song.append(p_lists) song.append(len(p_lists)) song.append(n_lists) song.append(len(n_lists)) song.append(e_lists) song.append(len(e_lists)) song.append(None_lists) song.append(len(None_lists)) # p/(p+n+e) の割合を計算 try: p_ratio1 = len(p_lists) / (len(p_lists) + len(n_lists) + len(e_lists)) except ZeroDivisionError: p_ratio1 = 0 song.append(p_ratio1) # p/全単語数 の割合を計算 try: p_ratio2 = len(p_lists) / (song_word_num) except ZeroDivisionError: p_ratio2 = 0 song.append(p_ratio2) # n/(p+n+e) の割合を計算 try: n_ratio1 = len(n_lists) / (len(p_lists) + len(n_lists) + len(e_lists)) except ZeroDivisionError: n_ratio1 = 0 song.append(n_ratio1) # n/全単語数 の割合を計算 try: n_ratio2 = len(n_lists) / (song_word_num) except ZeroDivisionError: n_ratio2 = 0 song.append(n_ratio2) # ポジティブ - ネガティブのスコア1を算出 score1 = p_ratio1 - n_ratio1 song.append(score1) # ポジティブ - ネガティブのスコア2を算出 score2 = p_ratio2 - n_ratio2 song.append(score2)
# グラフ作成
graph_data_list1 = []
graph_data_list2 = []
graph_data_list3 = []
graph_data_list4 = []
graph_data_list5 = []
graph_data_list6 = []
for song in song_list: # ポジティブの単語数 graph_data1 = [song[0], song[5]] graph_data_list1.append(graph_data1) # ネガティブの単語数 graph_data2 = [song[0], song[7]] graph_data_list2.append(graph_data2) # ニュートラルの単語数 graph_data3 = [song[0], song[9]] graph_data_list3.append(graph_data3) # 未分類の単語数 graph_data4 = [song[0], song[11]] graph_data_list4.append(graph_data4) # スコア1 graph_data5 = [song[0], song[16]] graph_data_list5.append(graph_data5) # スコア2 graph_data6 = [song[0], song[17]] graph_data_list6.append(graph_data6)
graph_list1 = dict(graph_data_list1)
graph_list2 = dict(graph_data_list2)
graph_list3 = dict(graph_data_list3)
graph_list4 = dict(graph_data_list4)
graph_list5 = dict(graph_data_list5)
graph_list6 = dict(graph_data_list6)
# plotlyでグラフ化
graphtitle = "ミスチル ネガポジ分析"
fig = go.Figure()
fig.add_trace(go.Bar(x=list(graph_list1.keys()), y=list(graph_list1.values()), name = 'ポジティブ単語数', yaxis='y1'))
fig.add_trace(go.Bar(x=list(graph_list2.keys()), y=list(graph_list2.values()), name = 'ネガティブ単語数', yaxis='y1'))
fig.add_trace(go.Bar(x=list(graph_list3.keys()), y=list(graph_list3.values()), name = 'ニュートラル単語数', yaxis='y1'))
fig.add_trace(go.Bar(x=list(graph_list4.keys()), y=list(graph_list4.values()), name = '未分類の単語数', yaxis='y1'))
fig.add_trace(go.Scatter(x=list(graph_list5.keys()), y=list(graph_list5.values()), name = 'スコア1', yaxis='y2', mode='markers'))
fig.add_trace(go.Scatter(x=list(graph_list6.keys()), y=list(graph_list6.values()), name = 'スコア2', yaxis='y2', mode='markers'))
fig.update_layout(title={'text': graphtitle})
fig.update_layout(xaxis={'categoryorder':'total descending'})
fig.update_layout(yaxis1=dict(side='left'), yaxis2=dict(side='right', showgrid=False, overlaying='y'))
fig.show()
# グラフをhtml形式で保存。
filename = "mrchildren-negaposi"
with open(filename + '.html', 'w') as f: f.write(fig.to_html(include_plotlyjs='cdn'))